
前言
PG19 里引入了一个很有意思的新东西:SQL/PGQ。
PGQ,全称是 Property Graph Query。这里的 PGQ 不是 PostgreSQL Query,别看见 PG 就自动脑补为 PostgreSQL。官方文档里也专门吐槽了一句,property graph 在图数据库领域通常也会被缩写成 PG,这对 PostgreSQL 用户来说多少有点容易串台。
Here, PGQ stands for “property graph query”. In the jargon of graph databases, “property graph” is normally abbreviated as PG, which is clearly confusing for practioners of PostgreSQL, also usually abbreviated as PG.
简单说,PG19 开始可以在 PostgreSQL 内核里定义 property graph,然后用图模式匹配语法去查询。
这事挺有意思。以前我们在 PostgreSQL 中想做图相关的事情,通常有几条路:
- 用普通表建点表、边表,然后手写一堆 join;
- 用递归 CTE 做层级、路径、上下游追踪;
- 用 Apache AGE 这类扩展,在 PostgreSQL 里跑 openCypher;
- 把数据同步到 Neo4j、JanusGraph、NebulaGraph 等专门图数据库。
PG19 的 PGQ 则提供了另外一种方式:数据仍然存在关系表中,但我们可以把这些表映射成一个图视图,然后用图查询方式去处理。
为什么数据库里会需要图查询
首先我们先了解一下其背景。关系型数据库最擅长的是表、行、列、约束、事务、关联等。这些东西非常强,支撑了几十年的业务系统。但现实世界里,很多问题天然不是”表格”的,而是”关系网状式”的。比如:
- 金融风控:账户 A 转给 B,B 又转给 C,C 最后转回 A,这是不是一个资金闭环?
- 社交网络:张三的朋友的朋友里,有哪些也是李四的同事?
- 供应链:某个零件故障,会影响哪些上游供应商和下游订单?
- 权限系统:一个用户通过角色、组织、项目组继承到了哪些权限?
- 知识图谱:一个实体通过若干关系连接到哪些概念、文档、事件?
- 推荐系统:买过这个商品的人,还和哪些商品、商家、活动有关?
当然,这些场景用 SQL 不是不能写。图在关系模型里完全可以表示:点是一张表,边也是一张表,点表有主键,边表通过外键指向两个点。连接表、多外键表、主外键关系,本质上都可以看成边。
让我们看一个典型的社交关系例子:
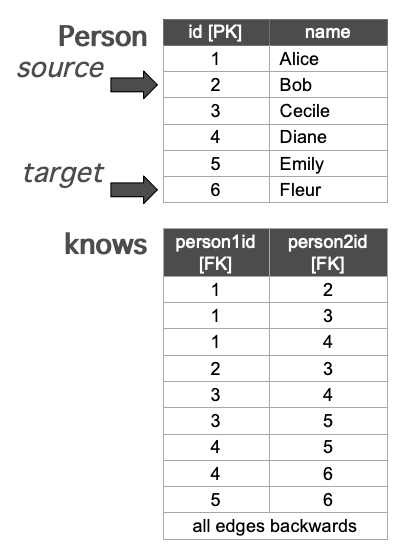
- Person 表里有 6 个人,每一行就是图里的一个点。
- knows 表有两列,表示 person1id 认识 person2id,所以一行 (1,2) 就代表一条边,Alice -> Bob
1 | CREATE TABLE person ( |
这就是一个很朴素的图。person 是点,knows 是边。
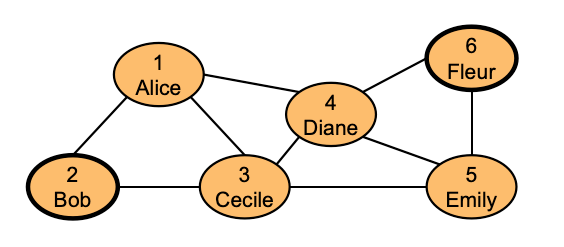
如果只是查 Bob 认识谁,一个 join 就够了;如果查 Bob 的朋友的朋友,再多 join 一次也还行。
但是假如现在我想问 “Bob 到 Fleur 最短隔了几层关系?”,也就是**从 Bob 到 Fleur 的最短路径是多少?**这就不是固定两跳、三跳能解决的问题了。在上图中,可以肉眼看到几条路径:
- Bob -> Cecile -> Emily -> Fleur
- Bob -> Cecile -> Diane -> Fleur
- Bob -> Alice -> Diane -> Fleur
这些路径长度都是 3 条边。所以这个例子的最短路径长度是:3,也就是 Bob 到 Fleur,最少需要经过 3 条 knows 边。但是现实情况是复杂的,”认识”这个关系通常是无向的。Alice 认识 Bob,也可以理解为 Bob 认识 Alice,所以我们还需要再插入一条 INSERT INTO knows (SELECT person2id, person1id FROM knows); 最终 knows 表变成”每条边都有正反两个方向”,即无向关系,也让关系表和图示保持一致,这样递归查询才能沿任意方向走。
以 PG 为例,要实现此场景,就得用 CTE 递归,大概长这样:

这段 SQL 的核心思想是
从 Bob 出发,每次沿着 knows 边向外扩展一跳;不断记录已经走过的路径;如果到达 Fleur,就停止;最后取最短路径长度。
可以看到,**图查询确实可以用关系模型和 SQL 表达,但写起来很别扭,优化起来也很困难。**光看上面这一坨 SQL 和逻辑,脑子稍微糊一点就容易绕进去,至少我第一眼看是很难受的。
也就是说,表结构本身并不复杂,复杂的是查询表达。这就是图查询存在的意义。关系型模型关心的是:这张表和那张表如何关联?而图模型关心的是:
- 这个点和哪些点通过什么边连起来?
- 从这里出发,沿着关系能走到哪里?
- 中间有没有环路、共同邻居、关键节点?
它不是为了取代 SQL,而是让关系网络这类问题表达得更自然。
图到底是什么
让我们先把概念捋一下。图一般由两类元素组成:
- 顶点:vertex,也常叫 node;
- 边:edge,也常叫 relationship。
顶点表示实体,边表示实体之间的关系,这些关系可以是”知道”、”购买”、”位于”、”工作于”、”提及”等等,这也是图数据库最核心的地方,关系不是隐藏在 JOIN 里,而是直接作为数据模型的一等公民。
另外,在 property graph 里,顶点和边还可以带:
- label:标签,用来说明元素类型;
- property:属性,用来保存具体字段。
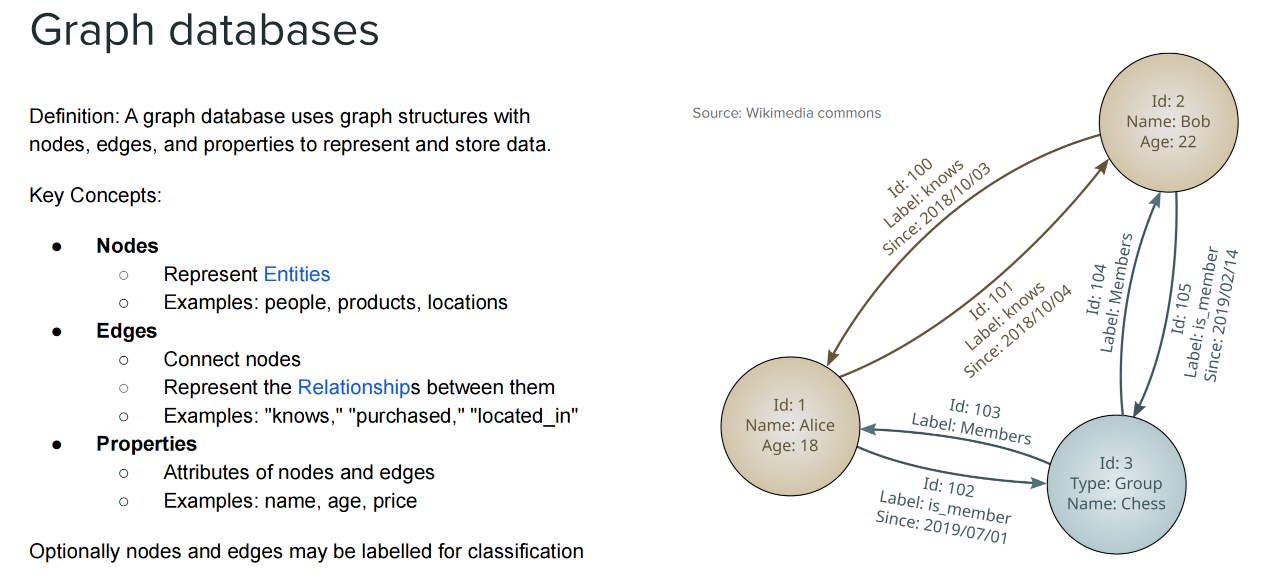
属性不只属于节点,也可以属于边。节点属性比较容易理解,但边也有属性。例如图里有一条边:Id: 100、Label: knows、Since: 2018/10/03,这说明这条关系本身也有信息:
- 谁认识谁
- 什么时候开始认识
- 这条关系的 ID 是多少
- 关系类型是什么
在关系数据库里,这通常需要一张中间表来表达,比如:
1 | CREATE TABLE knows ( |
但在图数据库里,这就天然是一条边:
1 | (:Person {name:'Alice'})-[:knows {since:'2018-10-03'}]->(:Person {name:'Bob'}) |
这就是 property graph 里的 property 的含义。
至于 Label,节点和边可以带标签,用于分类。比如节点可以有标签:
1 | :Person |
边也可以有标签:
1 | :knows |
在上图中可以看到:
- Alice、Bob 可以看成 Person 类型节点
- Chess 可以看成 Group 类型节点
- knows、is_member、Members 可以看成边标签
标签的作用类似关系数据库里的表名或类型名。
例如:
- (:Person)-[:knows]->(:Person)
- (:Person)-[:is_member]->(:Group)
这样查询时就可以指定:只查 Person 节点 或者 只查 is_member 关系。
关系表、图存储、PGQ
很多人一听图数据库,脑子里马上会想到 native graph database,也就是数据天然按点和边组织,边上直接带着相邻点引用。图数据库里经常提一个概念:Index-Free Adjacency。简单理解就是:从一个点找相邻点,不一定要靠全局索引反复查,而是可以通过边的邻接关系直接走过去。
这也是很多图数据库在深度遍历、路径搜索、关系扩散场景里有优势的原因。
但 PG19 的 PGQ 不是这个路子。官方文档说得很清楚:PG19 的 property graph 是定义在关系表之上的一种只读图视图。实际数据仍然存储在普通表、视图、外部表等关系对象里。CREATE PROPERTY GRAPH 不会把数据复制成一份物化图结构,注意重点:视图。
也就是说,PGQ 更像是:
1 | 关系表 |
PGQ 并不是将 PostgreSQL 突然变成一个”原生图存储数据库”,**而是让 PostgreSQL 在保留关系模型、事务、权限、优化器、生态工具的同时,多了一套标准化的图查询表达方式。**所以 PGQ 适合这些场景:
- 数据本来就在 PostgreSQL 关系表里;
- 业务主要还是 SQL,但某些查询天然是图模式;
- 不想为了几类关系查询单独维护一套图数据库;
- 想把图查询结果继续和普通表 join、过滤、聚合;
- 想跟 SQL 标准靠拢,而不是引入一套完全独立的查询语言。
这就是 PGQ 的定位。别神化,也别小瞧。
PG19 里的 PGQ 长什么样
PG19 里有两个核心东西:
CREATE PROPERTY GRAPH:定义一个 property graph;GRAPH_TABLE:在 SQL 查询里执行图模式匹配,并返回一张关系表。
官方文档里有一句很重要:GRAPH_TABLE 对外表现得像一个 table function。也就是说,它产生一个表,然后你可以继续 JOIN、WHERE、ORDER BY。
让我们小试牛刀一下,构造一个简单场景。有两张表:
bank_accounts:账户表;bank_transfers:转账流水表。
1 | CREATE TABLE bank_accounts ( |
如果用关系模型的方式来看,它就是这样:
- bank_accounts 是点表
- bank_transfers 是边表
- src_acct_id 是边的起点
- dst_acct_id 是边的终点
现在我们把它定义成一个 property graph:
1 | postgres=# CREATE PROPERTY GRAPH bank_graph |
这段 DDL 做了几件事:
bank_accounts映射成顶点;bank_transfers映射成边;account是账户顶点 label;transfer是转账边 label;SOURCE指向转出账户;DESTINATION指向转入账户;PROPERTIES指定哪些列作为图属性暴露出去。
现在我想查询 Alice 转给了谁,先看一跳关系:
1 | postgres=# SELECT * |
这个语法看起来就很像图:(Alice)-[transfer]->(谁)
如果用传统 SQL,大概是:
1 | postgres=# SELECT a.id AS src_id, |
这个例子还不复杂,所以 SQL 也很清楚。重点是当路径越来越长时,图语法会越来越自然。
比如我们要查:**Alice 转给谁,这个人又转给了谁?**PGQ 可以这样写:
1 | postgres=# SELECT * |
你看,路径结构一眼就出来了:
1 | Alice -> middle -> dst |
这类 SQL 如果用 join 写,当然也可以,但读起来就没有图模式那么直观,四个 JOIN,可读性相较于 PGQ 差的太多了。
1 | postgres=# SELECT a.name AS src_name, |
PGQ 让路径成为直观的表达对象,不需要别扭地在脑子里把 join 翻译成路径,而是在 SQL 里直接写路径。
PGQ 的几个关键点
结合官方文档,我觉得 PG19 PGQ 有几个点需要注意。
第一,property graph 是只读图视图。
CREATE PROPERTY GRAPH 只是定义图结构,不会物化数据。数据仍然在底层关系表里。你要插入、更新、删除数据,仍然操作原始表。
第二,边是有方向的。
PGQ 里 edge 有 source 和 destination。查询时:
()-[]->()按边的正向匹配()<-[]-()按边的反向匹配()-[]-()两个方向都可以匹配
方向含义不一样。官方文档里也说明了,不带方向的模式可以理解为匹配任意方向。
第三,label 不是表名。
默认情况下,表名或别名会暴露成 label,但你可以自己指定 label。比如 bank_accounts LABEL account,查询时写的是:(a IS account),而不是:(a IS bank_accounts)
第四,property 类似列。
PROPERTIES (id, name, balance) 会把这些列暴露成图属性,查询时可以写 a.name、a.balance。
第五,同名 label / property 有一致性要求。
如果多个元素表使用同一个 label,那么这些 label 暴露的属性数量、名称、类型需要一致。这个限制很好理解,否则同一个 label 查出来,字段一会儿是 text,一会儿是 int,后面就没法正常处理了。
第六,权限仍然看底层关系对象。
官方文档里提到,GRAPH_TABLE 访问底层关系对象时,权限按执行查询的用户判断,而不是只看 property graph owner。所以别以为给了 graph 权限,就能绕过底层表权限。是的,这点很 PG。
PGQ 会不会取代递归 CTE
另外一个问题是,PGQ 会不会取代递归 CTE?我觉得不会。
递归 CTE 仍然很有用。组织树、分类树、简单父子层级、物料清单 BOM,这些场景递归 CTE 很成熟,也很可控。
PGQ 更适合表达模式匹配:
- 点和边类型比较多;
- 关系方向比较重要;
- 查询问题更像找路径而不是展开树;
- 需要把多个实体关系串起来;
- 希望查询语法更贴近业务关系图。
PGQ 的性能
这是 DBA 最关心的问题。
PGQ 写起来更像图,那性能是不是就像图数据库一样?PG19 PGQ 底层目前还是 PostgreSQL 的关系存储、查询规划、执行器。数据没有变成原生图结构,所以性能上还是还是类似:
第一,边表索引仍然非常重要。
比如上方的银行转账图里,至少要考虑:
1 | CREATE INDEX ON bank_transfers(src_acct_id); |
如果常按金额过滤,也要考虑金额相关索引。
第二,路径越长,中间结果越容易爆。
图查询很容易出现组合爆炸。二跳还好,三跳开始就要小心,四跳五跳再加不限制条件,数据库可能就 OOM 了,其实这点和 CTE 递归是类似的。
第三,过滤条件尽量前推。
比如不要先匹配全图再过滤账户名、日期、金额。能在 element pattern 里写条件,就尽量把条件写进去:
1 | MATCH |
第四,先用 EXPLAIN 看计划。PGQ 最后仍然要落到 PostgreSQL 执行计划上。别因为语法长得像图,就忘了老本行,执行计划还是我们所熟悉的那一套。
1 | postgres=# explain SELECT * |
第五,不要拿 PGQ 去硬干所有图算法。PGQ 能解决一部分模式匹配问题,但毕竟不是专用的图计算引擎。
小结
PG19 的 PGQ,意味着 PostgreSQL 开始原生支持把关系数据映射成 property graph,并用 SQL 标准的方式进行图模式匹配。
对 AI 时代来说,SQL/PGQ 的意义尤其大。因为企业 AI 不只需要向量相似度,还需要实体关系、证据链、权限路径、数据血缘和上下文组织能力。PG19 把这些能力放进 SQL 标准查询体系里,相当于告诉大家:PostgreSQL 未来不只是存数据,也要更好地表达数据之间的关系。
参考
Graph databases, PostgreSQL and SQL/PGQ
PostgreSQL & Graph & Vector