在 18 的新版本中,包含了诸多惹眼特性,比如异步 I/O、BTREE Skip Scan、UUIDv7 等等,其实在 18 的新版中,还引入了一项很重要的特性 — NUMA 感知,一直以来,PG 就缺乏 NUMA 的可观测性,希望能看到 buffer 属于哪个 node、shared memory 分布、memory context 的 NUMA 信息等,PG 18 终于补足了这块拼图,让 NUMA 从玄学、从黑洞变为”可观测的工程问题”。
NUMA
Andres Freund 在 2024 年的 pgconf 上有一篇名为 NUMA vs PostgreSQL 的主题,介绍了 NUMA 的重要性以及未来的优化方向等。
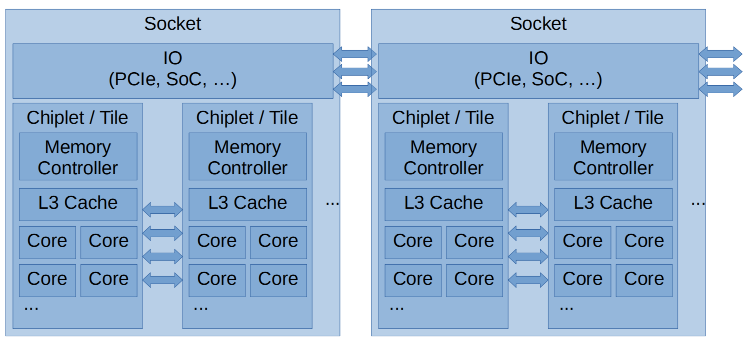
作者开门见山就提到 Moore’s law is dead:CPU 不再靠单核变快,而是靠更多 core、更多 chiplet/tile,虽然吞吐提升了,但是延迟问题更糟了,尤其是跨 chiplet、跨 socket 的访问延迟变大:
一个 socket 里可能有多个 chiplet / tile
每个 tile 有自己的 core、L3、内存控制器
不同 tile / socket 之间访问成本不同
作者也量化了大致的性能影响,简而言之 —— NUMA 最怕的不是”偶尔访问远端内存”,而是高频共享热点、锁竞争、反复跨节点访问同一批共享元数据,而这些又是 PG 很容易出现的。
本地内存基础延迟:约 80–140ns
跨 socket 再增加:约 80–100ns
跨 tile 再增加:约 30ns
最糟糕的是:争用锁
对哈希表等延迟敏感的结构来说,也比较糟糕
吞吐也会下降
如果数据已经在 L1/L2/L3 cache,差异则不太明显。
在 Linux 上,默认的访问策略是 Local node,真正分配发生在首次访问 (first touch),而不是 mmap() / malloc() 时,所以像 pg_prewarm() 这类操作会造成不平衡,也就是说,谁先 touch,页面就更可能落在谁所在的 NUMA 节点。
前面也提到,在 18 版本以前,**PG 最大的问题之一是数据库层面原生看不见 NUMA 的分布,既然看不见,那么就无法定位 NUMA 所带来的问题。**不过我们还是可以从操作系统层面进行观察,通过 /proc/$pid/numa_maps 看进程地址空间的 NUMA 分布,所以在 18 以前的版本,如果你怀疑某个 postgres 进程、shared memory、backend 有 NUMA 倾斜,可以先从这个文件入手。举个栗子
postgres=# with x as ( select numa_node, size::numericas sz from pg_shmem_allocations_numa where name='Buffer Blocks' ), s as ( selectsum(sz) as total from x ) select x.numa_node, x.sz, round(100* x.sz / s.total, 2) as pct from x crossjoin s orderby x.numa_node; numa_node | sz | pct -----------+-----------+------- 0|7553024|5.63 1|126672896|94.37 |0|0.00 (3rows)
-bash-4.2$ numactl --interleave=all pg_ctl start waiting for server to start....2026-03-05 18:25:07.037 CST [42338] LOG: redirecting log output to logging collector process 2026-03-05 18:25:07.037 CST [42338] HINT: Future log output will appear in directory "log". done server started
postgres=# with x as ( select numa_node, size::numeric as sz from pg_shmem_allocations_numa where name='Buffer Blocks' ), s as ( select sum(sz) as total from x ) select x.numa_node, x.sz, round(100 * x.sz / s.total, 2) as pct from x cross join s order by x.numa_node; numa_node | sz | pct -----------+----------+------- 0 | 67112960 | 50.00 1 | 67112960 | 50.00 | 0 | 0.00 (3 rows)
这一次各位便可以观察到 —— 同样的操作,内存均匀多了!根据 Andres Freund 实验结果: