
前言
对于 pgvector,不管是 IVFFlat 还是 HNSW,对于 vector 类型,都有着明确的 up to 2,000 dimensions 的限制 — 即最大 2K 维,那么为何会有这样的限制?
先入为主的片面
需要注意的是,前面提到的 2K 维限制是索引层的限制,而不是向量列本身的存储上限。pgvector 文档里明确区分了 vector 类型本身最多可到 16,000 维,但可被 HNSW / IVFFlat 索引的 vector 只能到 2,000 维。通过翻看源代码,代码里是直接写死成常量的:
- src/hnsw.h:#define HNSW_MAX_DIM 2000
- src/ivfflat.h:#define IVFFLAT_MAX_DIM 2000
另外,在 CHANGELOG 里还能看到这个上限的演进历史:
- 在 0.4.0 里,vector 本身最大维度从 1024 提升到 16000
- 但 index 的最大维度只从 1024 提升到 2000
那么为何会有这样的设计呢?在 Best practices for using pgvector 这篇 Topic 里,有这样一段内容
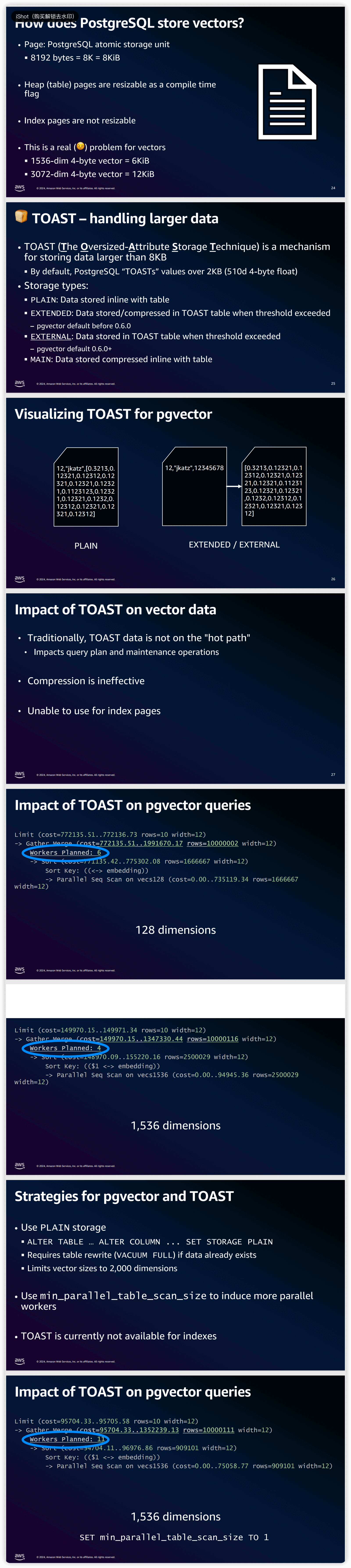
第一页中的 “Index pages are not resizable” 不够严谨,更准确地说应该是:PostgreSQL 的 BLCKSZ 是全局 page size,heap 和 index 都基于它,所以编译期间指定 blocksize 即可。对于 vector 类型,在代码中是这么定义的
1 | typedef struct Vector |
所以对于 vector 类型会很占空间,大约是 4 * dimensions + 8 bytes
- 1536 维 = 6144 bytes,约 6KiB
- 3072 维 = 12288 bytes,约 12KiB
一旦维度很高,单个向量值本身就已经接近甚至超过默认 8KB page 的量级。不过由于 PG 特有的 TOAST 机制,表数据可以靠 TOAST 处理大对象,在 pgvector 0.6.0 版本以后,默认的策略从 EXTENDED 改为了 EXTERNAL,即超过阈值则存储到 TOAST 中,但是一旦使用了 TOAST,又会带来新的问题,正如上方图片中所述:
- TOAST data is not on the “hot path” —— 当向量被 TOAST 到外部后,读取它不再是简单地从 heap tuple 里顺手拿出来,而是要额外 detoast,需要更多开销,对于向量查询来说更甚,因为向量距离运算需要频繁读取完整向量和做大量 float 运算
- Compression is ineffective —— embedding 向量本质是很多 float4,数值分布也比较随机,不像常规文本那样有大量可重复模式,所以压缩往往收益一般,因此高维向量即使走 TOAST,也未必能靠压缩解决太多空间问题,或许这也是为什么官方从 EXTENDED 改为 EXTERNAL 的原因
- Unable to use for index pages —— 这个是最重要的一点,**索引结构不能依赖 TOAST 机制来容纳超大的索引键。**索引项不能说”先塞个外部 TOAST 指针进去,然后靠 TOAST 表完成索引比较/导航”,这与索引的简洁高效的设计理念就背离了
再后面几页描述了 高维向量触发 TOAST 之后,会影响优化器和执行器的行为。图里大意是:
- 128 维时,Workers Planned: 6
- 1536 维时,Workers Planned: 0
- 然后通过 set min_parallel_table_scan_size to 1,1536 维又能计划并行
当向量被 TOAST 后,情况会更复杂:
- 主表上的 width 估算未必能充分体现 detoast 代价
- 真实执行成本和 planner 估算可能出现偏差
- 某些场景下 planner 可能不愿意选并行
所以为了缓解 TOAST + 大向量组合的问题:
- 设置为 PLAIN 策略,避免压缩和行外存储,但是对于存量表,需要重写才能生效,这样做可以让查询路径更友好,读取向量更直接以及更少的 detoast 开销;同时建议维度限制在 2K 维,因为 vector 本质上是 float4 数组,1 维大约 4 字节,2000 维 ≈ 8008B
- 调整 min_parallel_table_scan_size,”诱导”优化器走并行
索引为何是 2000 维
那么问题来了,为何索引也有 2K 维的限制?
索引项要直接参与索引结构组织和查找,不能指望像表那样把超大的键值外置到 TOAST 后再轻松工作。PG 对 B-tree 甚至明确说了:单个索引项不能超过大约 1/3 个页,因为页面必须至少容纳 3 个项,索引里放进去的内容,必须足够小、足够紧凑,不能靠外部大对象机制兜底,所以索引项不能无限大,但是向量又天然很大,2000 是 pgvector 在这种约束下,再结合自身实现,明确设下的工程上限
翻看 pgvector 的 issue,比如
- Increase max vectors dimension limit for index
- OpenAI’s text-embedding-3-large model not compatible with pgvector 5.1,这个 issue 核心很简单,提问者想把 HNSW 的 2000 维硬限制改掉,用来支持 OpenAI 的
text-embedding-3-large(3072 维),因为维度不兼容,但只改宏定义后 (简单的将#define HNSW_MAX_DIM 2000改为\#define HNSW_MAX_DIM 8192),插入索引项时失败了,提示 failed to add index item to “xyz_cosine_idx”,报错的地方是 hnswinsert.c,报错failed to add index item to ...是在执行PageAddItem(...)或PageIndexTupleOverwrite(...)失败时抛出的。也就是说,失败点不是”前置维度检查没通过”,而是:索引 tuple 真正往 page 里塞的时候塞不下,或者页内布局无法满足要求。
那么我再改大一下 blocksize + 调整宏定义不就可以了?Indexing vectors have size 2048 这个 issue 里面就是这么做的,可惜仍然报错了。所以并不是那么简单,只是把前门打开,后门还堵着。
小结
放开常量 + 调大 block size 并不等于支持更高维的索引,还要看官方是否连同索引项布局、页内存组织、插入路径、构建路径一起做了适配。如果未来 pgvector 官方不仅放开了 2000 维限制,而且连底层索引实现也一并适配,同时又把 block size 调大,那么“页大小 + 扩展硬限制”这两层障碍有可能被解除。
但这仍然不等于:
- 一定对所有高维模型都稳定可用
- 一定性能很好
- 一定比
halfvec/ 降维 / subvector 更优
因为官方目前给出的现实建议仍然是:超过 2000 维时,优先考虑 halfvec、binary quantization、subvector 或降维。
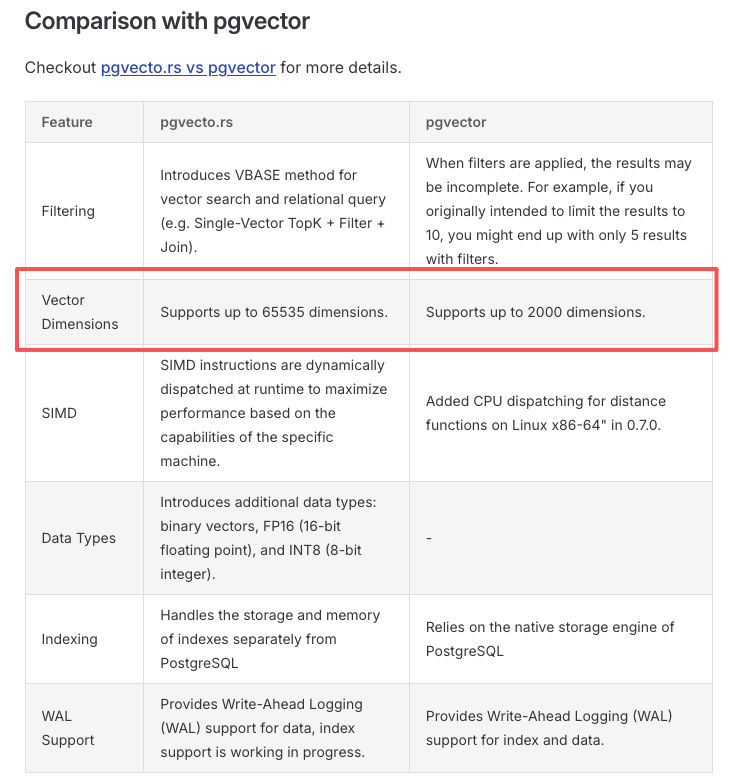
也可以考虑其他插件,比如 VectorChord / pgvecto.rs: 官方对比页写的是最高 65535 维
vectorscale 不是一个新的向量数据类型,它是给 pgvector 增加 DiskANN 索引。 所以它虽然文档里有 num_dimensions,但从公开 issue 看,当前实现并没有把高于 2000 维的问题真正放开。
参考
https://github.com/pgvector/pgvector