
前言
PG 中的元组是按照列定义顺序存储的,而不同数据类型有不同的长度和对齐要求;如果列顺序不合理,就会产生额外 padding,导致行变大、page 中可容纳行数减少、I/O 增加、cache locality 下降等,合理调整列顺序,可以减少 padding,从而节省磁盘空间。并且当 PG 在访问某一列时,必须根据前面列的长度、NULL 情况和 alignment 规则,计算该列在 tuple data area 中的 offset。列顺序影响这个 offset 计算,也影响每行实际占用空间。
道理我们都懂,但是到了真实生产中,具体如何调整却成为了一个难题,最近笔者就发现了这样一个十分有趣的插件 pg_column_tetris
- Warns on suboptimal CREATE TABLE statements during development
- Enforces strict alignment in CI/CD pipelines
- Audits existing tables and generates optimized migration scripts
A PostgreSQL extension that enforces optimal column alignment to minimize row padding waste.
简而言之,这个插件在我们创建非最优的表时会自动打印出提示信息,并且给出我们具体的建议。
背景知识
让我们简单重温下背景知识,Alignment and Padding 目的不是为了”让格式整齐”,而是为了让CPU 访问更高效、缓存利用更好、避免非对齐访问带来的额外代价以及保证不同硬件架构上的正确性和性能,在 x86 上,很多非对齐访问虽然允许,但可能有性能代价;在 ARM、SPARC 等架构上,非对齐访问的成本可能更明显,甚至某些场景会触发异常或需要软件修正。
假设有一个表,其中包含四个 smallint 类型列和一个 bigint 类型列。当一个较小大小的列 (例如 smallint,2 字节) 与一个较大大小的列 (例如 bigint,8 字节) 相邻时,Postgres 会在 smallint 类型列中添加 6 个字节的填充,以满足与相邻 bigint 类型列 8 字节的对齐要求。然而,这 6 个字节的填充空间可以通过重新排列 bigint 类型列之前的其他三个 smallint 类型列来利用:

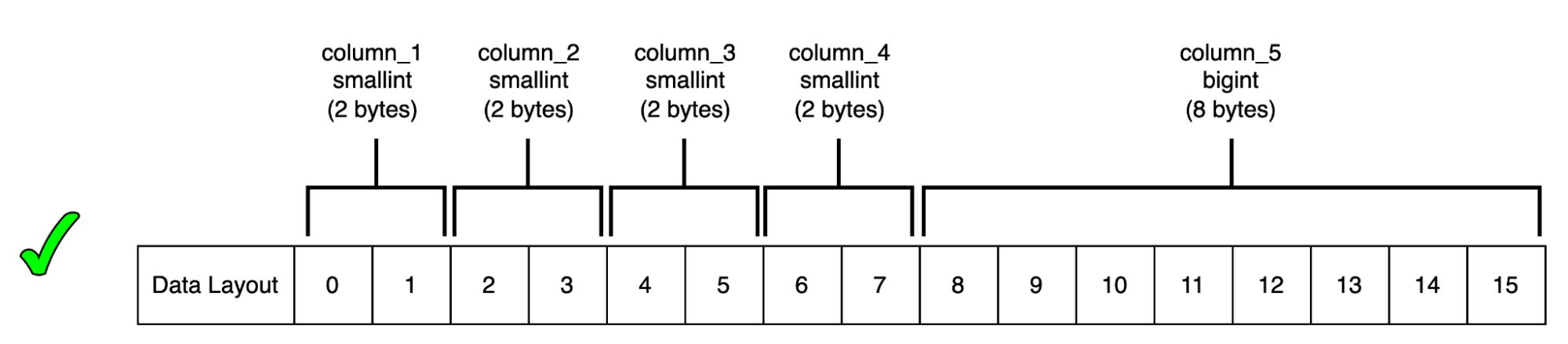
所以,如果列顺序很随意,padding 浪费可能会被放大。尤其是亿级、十亿级行数的表,单行多浪费几个字节,整体就是 GB 甚至 TB 级别的额外空间。
同理,从 CPU 的角度来看,现代 CPU 不是一个字节一个字节地访问内存,而是以固定大小的 chunk 读取,比如 word、cache line 等;常见粒度可能是 4、8、16 字节,而现代 64 位架构中 8 字节 word 很常见,如果一个 8 字节整数从 0x1002 开始,CPU 可能需要读取两个 8 字节块;如果它从 0x1000 或 0x1008 开始,只需要一次读取。

小试牛刀
有了这个背景知识,让我们简单验证一下
1 | postgres=# CREATE TABLE example ( |
现在让我们根据其建议重新调整一下列顺序
1 | postgres=# CREATE TABLE optimized_example ( |
可以看到,这次不仅没有了提示信息,单行的长度也小得多了,足足少了 10 字节。
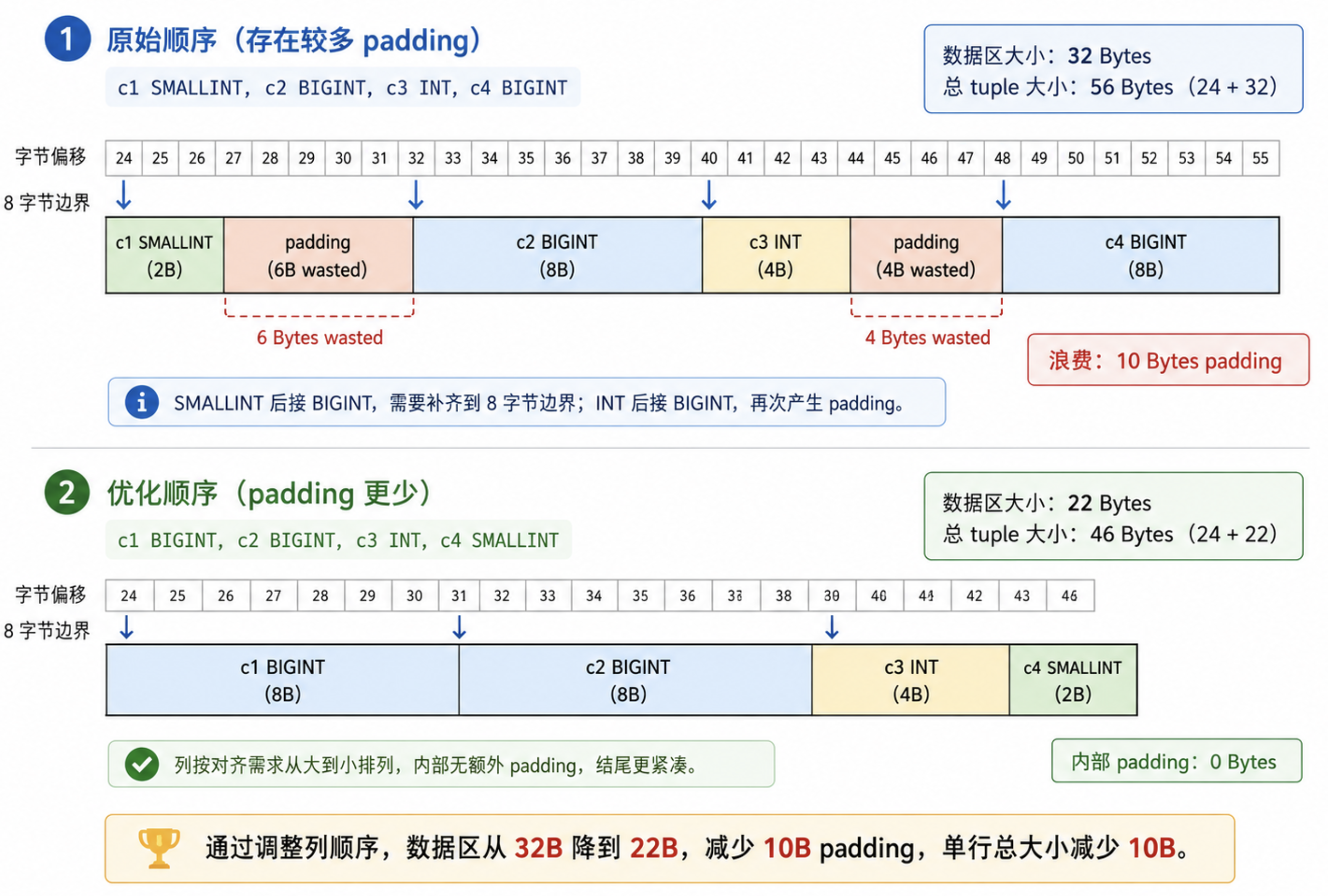
小结
根据最佳实践
- 大的 fixed-length 字段优先放前面
- 小 fixed-length 字段放后面,减少中间 padding
- 大型变长字段通常放最后,固定字段靠前有利于 offset 计算和 tuple 紧凑性
当然不要过度牺牲可维护性,列顺序优化不能机械到让表结构难以理解。比如业务上高度相关的一组字段,如果拆得太散,可能影响可读性,可以先按业务主路径组织字段:主键 / 分布键 / 时间 / 状态 / 常用过滤字段 / 业务属性 / 大字段,然后在每个组内按 alignment 做微调。