
前言
大学时,我了解到使用预备语句是最佳实践 —— 主要是因为它们有助于防止 SQL 注入,并且大多数驱动程序都默认支持。很多人强调这是使用它们的关键原因,但我从未完全理解它们背后的工作原理。所以,今天,一个空闲的星期六,我决定深入研究一下它们。
目录
消息流概述
- PostgreSQL 客户端 — 服务器通信简介
- 关键阶段:启动、查询和关闭
- 客户端和服务器之间交换的常见消息类型
简单查询协议
- 消息流:解析、计划、执行
- 探索关键特征
扩展查询协议
- 消息流:解析、绑定、执行、同步
- 一些概念验证 (Proof of Concept):计划复用与 SQL 注入防护
消息流概览
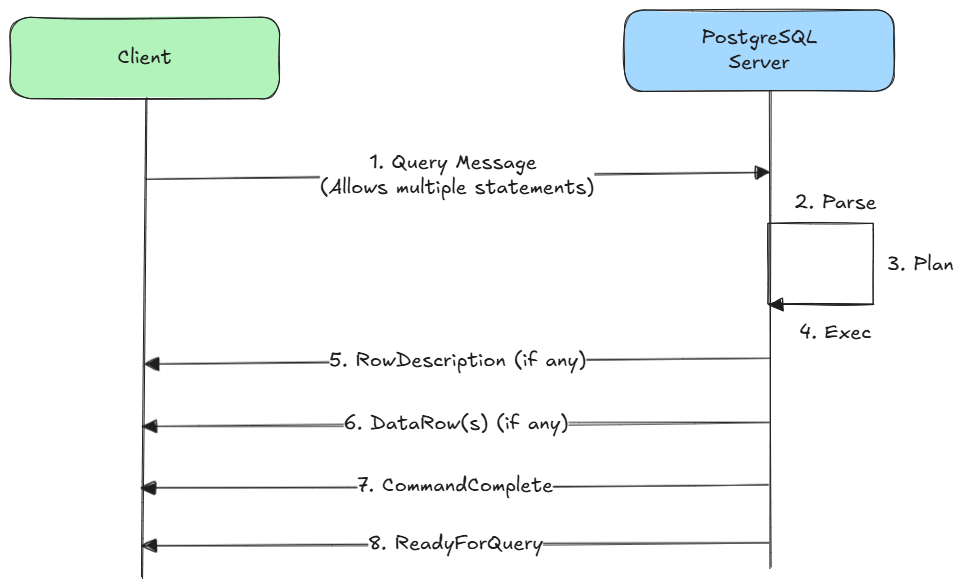
PostgreSQL 的消息流遵循典型的客户端—服务器模型,包括三个主要阶段:启动、查询和关闭。(更多内容: message flow)

启动阶段:
- 客户端首先与服务器进行 TCP 握手,建立基础的 TCP 连接。
- 根据配置,客户端可能会进行一次 SSL 握手,从而在传输过程中对数据进行加密。
- 客户端向服务器发送一条 StartupMessage,其中包含用户名、目标数据库等信息。
- 服务器回应一个 认证请求 (可能是 SASL、明文密码、或密码哈希方式)。
- 客户端按照要求的认证方式,发送对应的凭据。
- 当认证成功后,服务器会为该会话 fork 出一个新的后台进程,并发送 BackendKeyData 消息给客户端,其中包含该进程的 ID。
- 服务器再发送一条 ReadyForQuery 消息,表示已经准备好接收查询
查询阶段:
- 客户端通过 简单查询协议 或 扩展查询协议 来发送查询。
- 服务器接收到查询后,进行 解析、规划、执行 等操作 (不同协议下的细节不同)。
- 服务器发送 RowDescription 消息,描述结果集的列结构。
- 随后服务器可能会发送 0 行或多行 DataRow 消息,每条消息对应结果集中的一行数据。
- 服务器再发送 CommandComplete 消息,表示该查询已成功执行完成。
- 最后,服务器再次发送 ReadyForQuery 消息,通知客户端它已经准备好接收下一条查询。
查询阶段: 客户端通过简单协议或扩展协议发送查询。服务器处理完查询,返回结果,然后发出准备进行下一个查询的信号。
关闭阶段: 客户端发送”终止”消息以关闭连接。
简单查询协议 (或者 Simple Query)
在前面的 消息流概览 中,我们已经对查询的整体流程做了一个高层次的介绍。接下来,我们将更深入地探讨 简单查询协议 的具体工作机制。
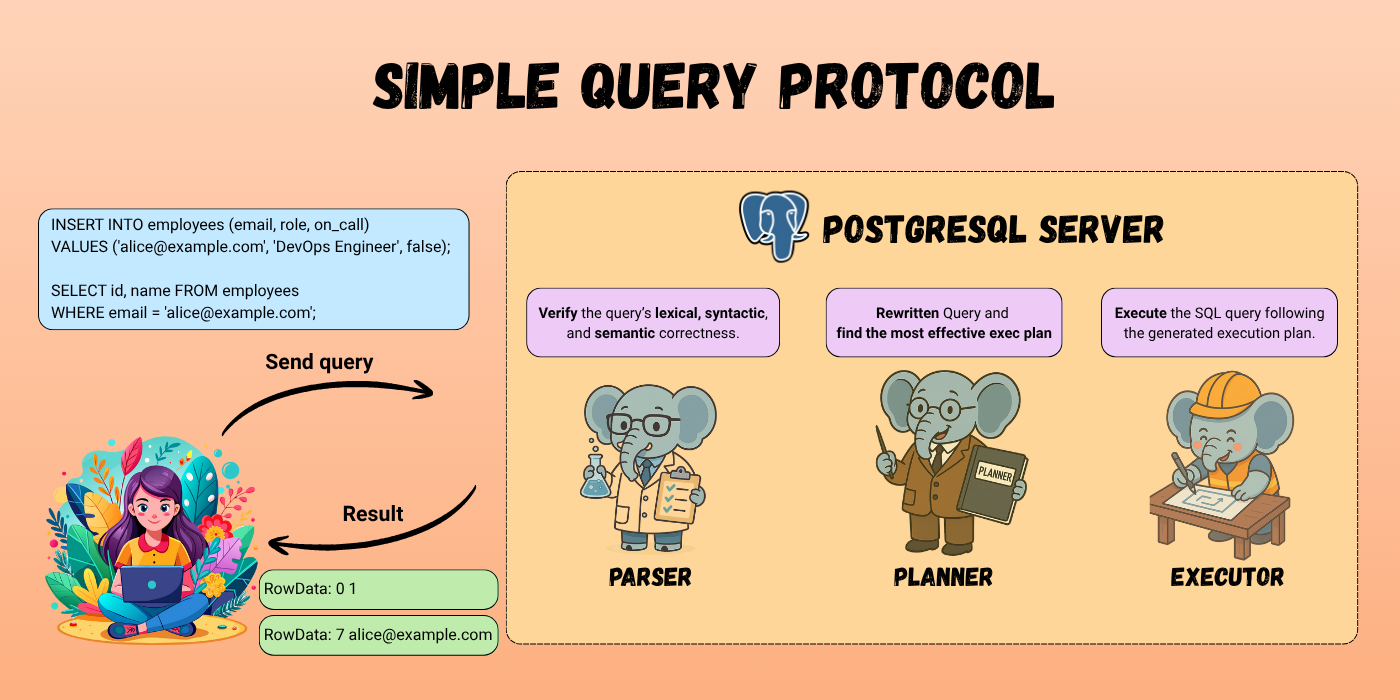
🔍 简单查询协议消息流
当 PostgreSQL 接收到一条包含多个语句的查询时,它会按照顺序逐个处理。每个语句都会经历三个阶段:解析、规划、执行。
- 解析:验证 SQL 的语法和语义,并生成一棵解析树。
- 规划:为查询生成并优化执行计划,以提高执行效率。
- 执行:执行计划并将结果返回给客户端。
📝 主要特性
- 使用纯文本 SQL 字符串 —— 客户端将整个 SQL 命令作为一条完整的文本字符串发送给服务器。
- 可包含多个语句 —— 各语句之间通过分号分隔。
- 顺序执行 —— PostgreSQL 会严格按照语句在 SQL 中出现的顺序依次执行。
- 三阶段处理 —— 每条语句都会经历 解析 → 规划 → 执行 这三个步骤。
- 立即返回结果 —— 每条语句执行完成后,服务器会立即将结果返回给客户端。
🧪 让我们通过实验来探索
初始化数据库 (我使用的是 PostgreSQL 17)
1 | -- Create a simple employees table |
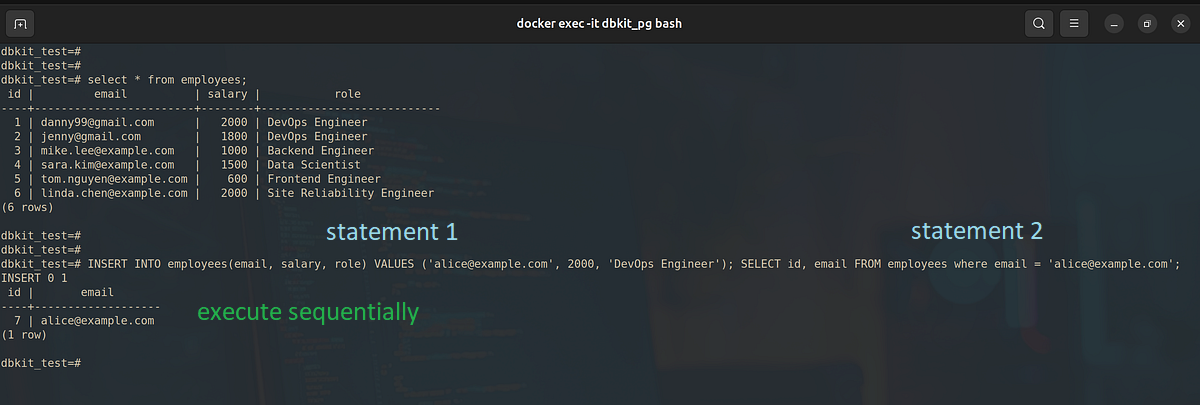
发送以下两个语句,PostgreSQL 将依次返回两个结果。
1 | INSERT INTO employees(email, salary, role) |
扩展查询协议
❓ 常见疑问 —— “当查询之间只是参数不同的时候,难道还需要每次都重新解析、生成计划并执行吗?”
这正是 扩展查询协议 存在的原因。

🔍 简单查询协议消息流
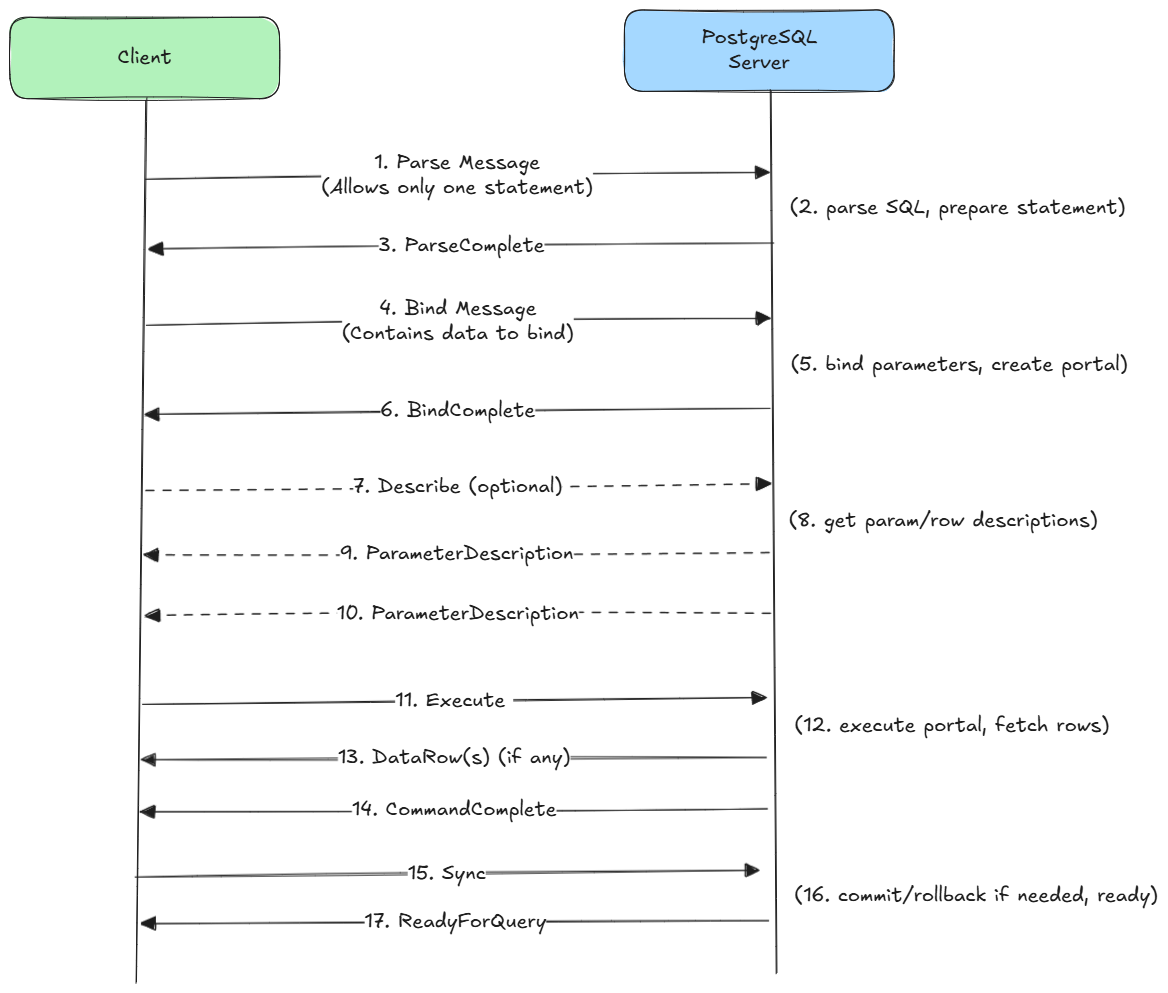
为了避免重复做相同的工作,我们只需要对查询 解析和生成执行计划一次,然后在后续执行中直接复用这个计划,只替换不同的参数即可。这种方式既直接又高效。
当 PostgreSQL 通过 扩展查询协议 接收到查询时,处理流程会被拆分为几个独立的步骤:
- 解析阶段:与简单查询协议类似,但这里还会运行 Planner,生成一个与参数值无关的通用执行计划 (Generic Plan)。
- 绑定阶段:将实际参数绑定到预备语句上,创建一个 Portal;此时优化器会决定是直接复用通用计划,还是基于参数生成一个新的自定义计划 (Custom Plan)。
- 执行阶段:执行 Portal,运行计划并返回结果。
- 同步阶段:标记扩展查询流程的结束,后端进程会在此时完成事务状态的收尾,并向客户端发送 ReadyForQuery 消息。
📝 主要特性
- 一次只允许执行一条 SQL 语句。
- 执行过程被拆分为多个步骤:解析→ 绑定→ 执行→ 同步。
- 基于预备语句:查询只需解析和生成计划一次,在同一个连接中即可复用计划并替换不同参数。
- 预备语句不能跨不同的后端进程共享。
- 有助于防止 SQL 注入 —— 因为查询结构和数据参数是分开的。
🧪 概念验证:对比简单查询协议与扩展查询协议
- 在扩展查询协议中,每次只能执行一条 SQL 语句。
由于 psql 在将语句发送给 PostgreSQL 之前,会先根据分号把语句拆分开,所以在交互模式下,我们无法在一条 PREPARE 命令里写入多个查询。为了演示这种行为,我会用一个简单的 Go 程序,并借助 pgx 驱动来做示例。
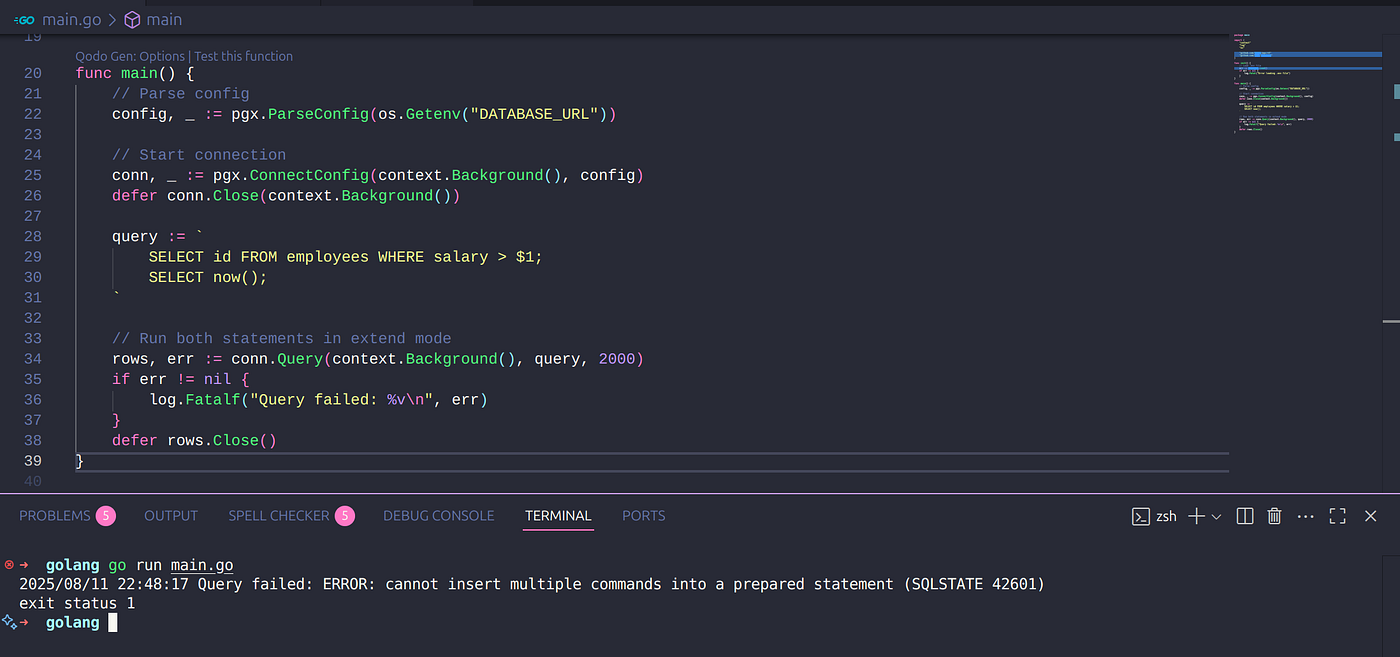
- 在不同参数下复用执行计划
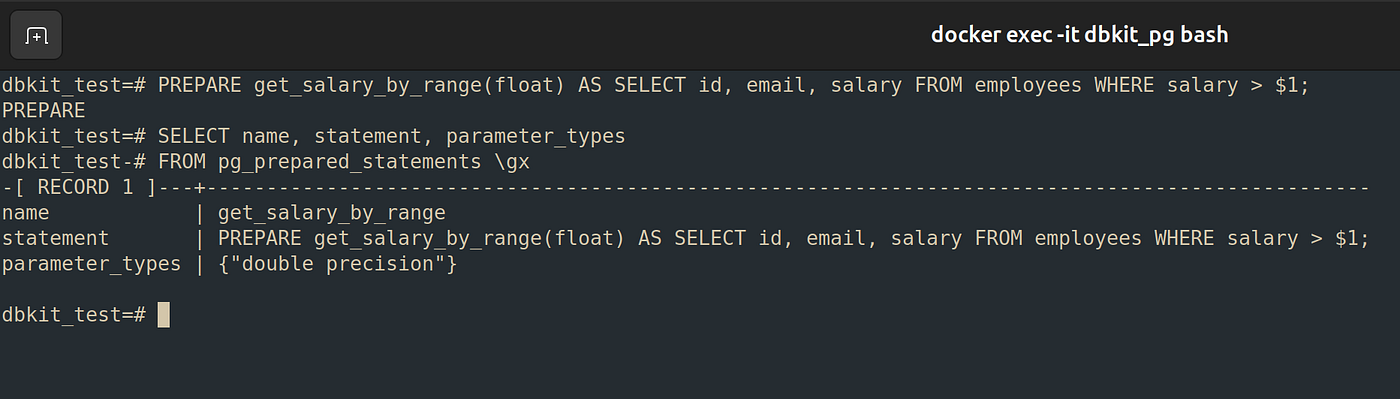
接下来,我们创建一个 预备语句(Prepared Statement)。需要注意的是,预备语句只在当前连接存活期间有效,一旦连接关闭,它就会失效。
1 | -- Create prepared statement to get employees with salary above given value |
在下图的右侧可以看到:在执行了前五次查询之后,第六次执行时,PostgreSQL 不再针对具体的参数值生成 自定义计划 (Custom Plan),而是直接使用了一个 通用计划 (Generic Plan),其中包含过滤条件:Filter: (salary) > $1
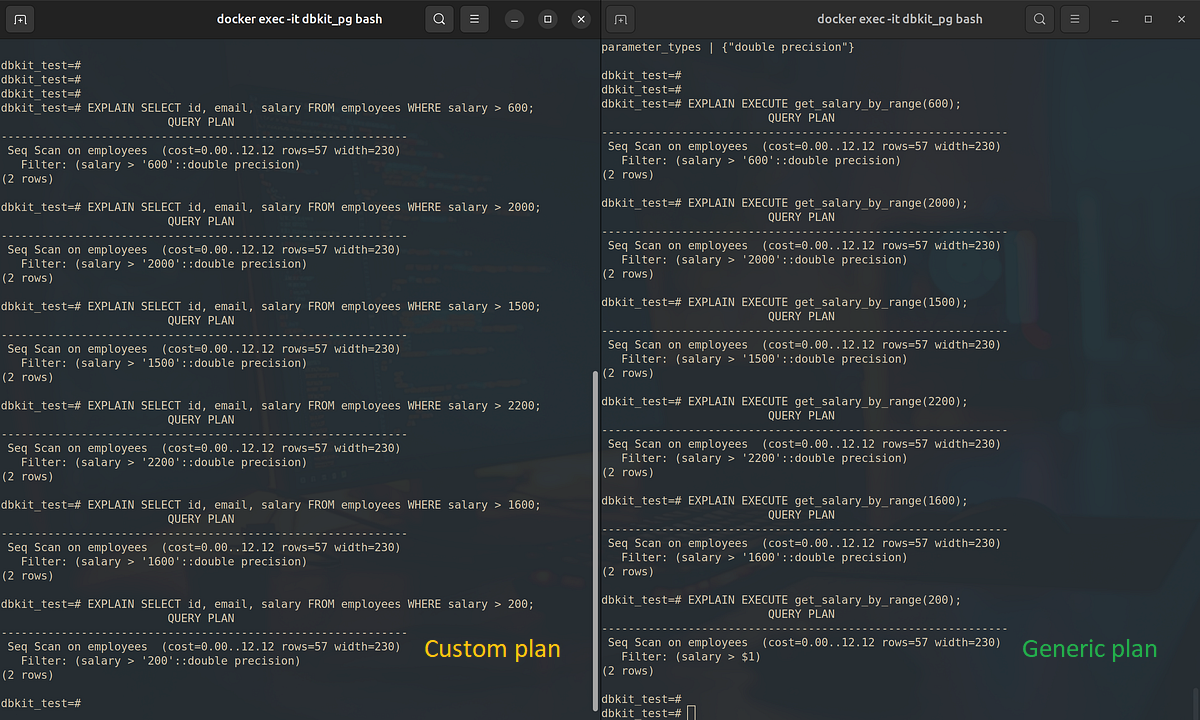
PostgreSQL 还允许我们查看使用通用计划时的执行次数统计数据。
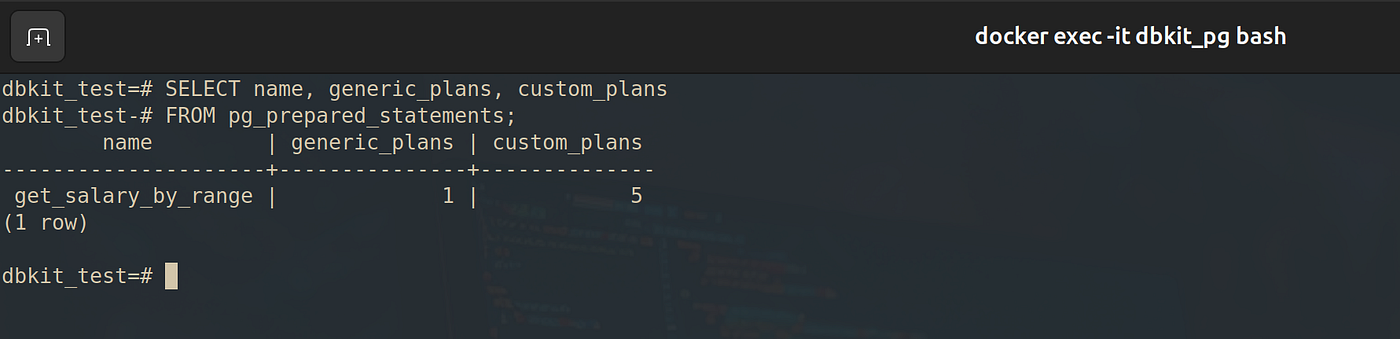
- 通过分离查询结构与数据参数,有效防止 SQL 注入
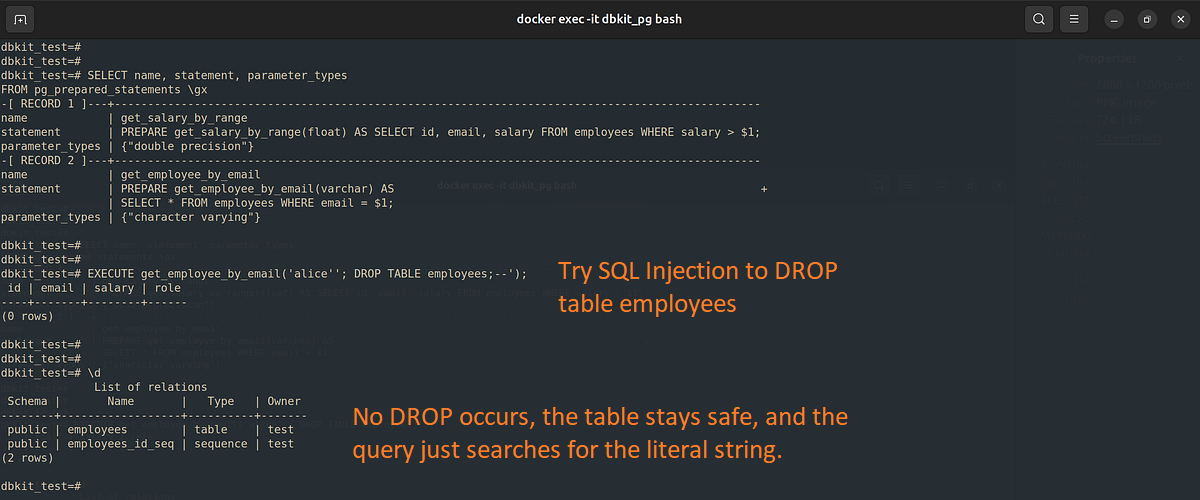
1 | -- Create a prepared statement to get employees by email |
如果使用 简单查询协议,并直接把用户输入拼接到 SQL 字符串中,在这种情况下,如果当前用户权限足够高,就会导致表被删除:
1 | -- If using concate string |
而在 预备语句 的模式下,整个输入将会被当作普通字符字面量进行处理,仅仅作为 email 列的匹配条件。因此, DROP TABLE 语句不会被执行。
结论
扩展查询协议通过允许查询只进行一次解析与计划,然后在不同参数下复用执行计划,从而提升了 PostgreSQL 的性能。这种方式减少了反复解析和生成计划带来的开销,非常适合 重复执行 或 参数化查询 的场景。
致谢
感谢你花时间读完这篇文章。
希望这些内容能为你理解 PostgreSQL 的查询协议带来一些有价值的启发。
如果你有任何反馈或问题,欢迎随时交流!
🛠️ 保持好奇,才能不断精进。