
前言
各国法律法规比如 GDPR(欧盟)、CCPA(美国)、网络安全法/个人信息保护法(中国) 都要求企业妥善保护用户隐私,而在企业数据库里往往存放着敏感数据 (如身份证号、手机号、银行卡号、医疗记录等)。如果直接将这些数据暴露给开发人员、测试人员,就可能造成隐私泄露、合规风险,即使在公司内部,也不能所有人都访问完整的真实数据,因此,这就涉及到了数据脱敏。在 PostgreSQL 生态中不乏有大名鼎鼎的 PostgreSQL Anonymizer,也有着小巧精悍的命令行工具 pganonymize,还有 pganonymizer 等等,那么这么多轮子,如何选型?各自都适用于什么场景?
pganonymize (rheinwerk-verlag)
首先是 pganonymize,基于 python 的一款 CLI 工具 + YAML 配置,可用于批量清洗数据库,官方文档:https://pganonymize.readthedocs.io/en/latest/schema.html
A commandline tool to anonymize PostgreSQL databases for DSGVO/GDPR purposes.
| Field | Value | Provider | Output |
|---|---|---|---|
first_name |
John | choice |
(Bob|Larry|Lisa) |
title |
Dr. | clear |
|
street |
Irving St | faker.street_name |
Miller Station |
password |
dsf82hFxcM | mask |
XXXXXXXXXX |
credit_card |
1234-567-890 | partial_mask |
1??????????0 |
email |
jane.doe@example.com | md5 |
0cba00ca3da1b283a57287bcceb17e35 |
email |
jane.doe@example.com | faker.unique.email |
alex7@sample.com |
phone_num |
65923473 | md5 as_number: True |
3948293448 |
ip |
157.50.1.20 | set |
127.0.0.1 |
uuid_col |
00010203-0405-…… | uuid4 |
f7c1bd87-4d…. |
举个栗子,假设有如下几张表,内容如下:
1 | anon_test=# select * from orders; |
我们需要在 YMAL 文件中定义脱敏规则,以及相应的 provider:
1 | tables: |
执行之后,pganonymize –schema=myschema.yml –dbname=anon_test –user=postgres –password=123 –host=127.0.0.1 –port=54344 -v,数据便会被相应地脱敏:
1 | anon_test=# select * from profiles; |
可以看到,pganonymize 是命令行工具,基于配置文件定义规则,然后执行 TRUNCATE/UPDATE 来脱敏数据。
pg-anonymizer (rap2hpoutre)
另一款工具是 pg-anonymizer
Export your PostgreSQL database anonymized. Replace all sensitive data thanks to faker. Output to a file that you can easily import with psql.
与 pganonymize 类似,基于配置文件,可以列级脱敏,内置规则较多,比如:faker(名字、地址)、哈希、截断,专注于 GDPR 合规场景。笔者没有具体使用,光看其文档:
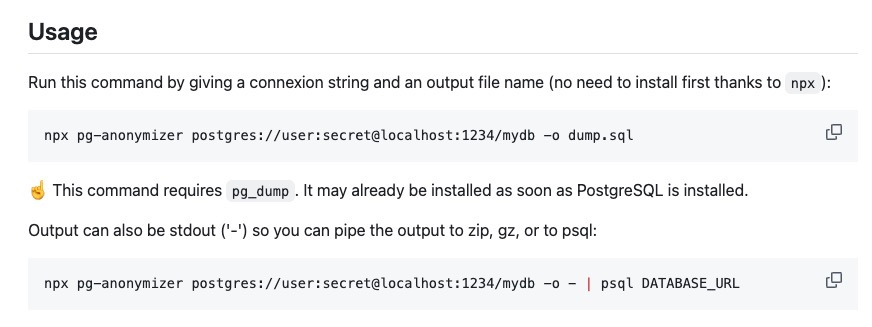
使用方法和 pganonymize 类似,不过是脱敏导出为 SQL,再导回数据库中的方式,这种方式的优点不言而喻,不具备破坏性,不会破坏原有数据。有趣的是,在 README 中,作者写明了为何他要去开发这一款工具
There are a bunch of competitors, still I failed to use them:
postgresql_anonymizermay be hard to setup and may be cumbersome for simple usage. Still, I guess it’s the best solution.pganonymizefails when it does not usepublicschema or columns have uppercase characterspganonymizeralso fails with simple cases. Errors are not explicit and silent.
此处提及了 pganonymize 不支持 public 以外的 schema,笔者也进行了验证,确实如此,虽然可以通过一些 workaround 解决,比如库级、用户级设置 search_path,但是始终很繁琐,最好能够在 YAML 文件中支持指定模式名。
1 | psycopg2.errors.UndefinedTable: relation "myschema.customers" does not exist |
pgantomizer
这一款工具笔者不做过多介绍了,2 年前的版本了,pg-anonymizer
PostgreSQL Anonymizer
最后介绍的便是大名鼎鼎的 PostgreSQL Anonymizer,出自 dalibo 实验室,最新的 2.0 基于 RUST + PGRX 重构,在安全性和稳健性上面有优势,使用 SECURITY LABEL 实现,并且其支持的特性和功能是最多的,官方文档:https://postgresql-anonymizer.readthedocs.io/en/stable/:
- Anonymous Dumps (导出脱敏 SQL)
- Static Masking (永久脱敏)
- Dynamic Masking (根据用户角色动态脱敏)
- Masking Views (为不同角色提供脱敏视图)
- Masking Data Wrappers (对外部数据源也能应用脱敏逻辑)
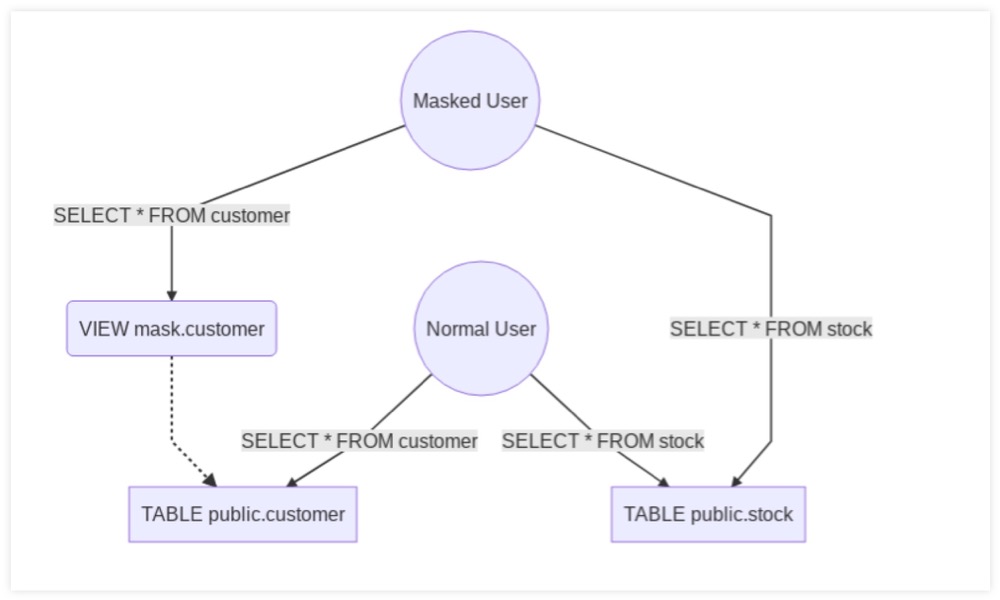
并且提提供丰富的脱敏函数,如替换、随机化、模拟(faking)、部分混淆、噪音添加、模糊泛化,甚至可自定义函数。在 1.x 的版本中,其实现还比较简陋,基于视图:
它禁止了被 mask 的用户读取原来的 schema,而允许它读取插件创建的两个 schema。并且它还设置了 search_path 这个参数,使得在 mask 这个 schema 下创建的 view 可以被优先读到。
实现原理类似如下:
并且还有一个很大的限制,仅支持一个 schema 进行脱敏,2.0 版本用 Rust + PGRX 全面重写,带来内存安全、性能与可维护性的提升;动态脱敏等策略因此在执行层面更“紧凑/高效”,并且正式支持了多个 SCEHMA,也不再是视图的方式,我个人也很喜欢其 Conditional Masking 的功能,在函数体内可以实现类似 CASE WHEN 的效果,与 PostgreSQL RLS 结合,可以实现基于用户角色实现差异化显示。但是 2.0 也有其限制,比如对于 Masked 用户,无法使用 Explain,但是这通常并不是太大的问题,性能上也会有些许损耗,具体取决于有多少个 Policy。
If you apply 3 or 4 rules to a table, the response time for the masked users should approx. 20% to 30% slower than for the normal users.
比对
| 工具 | 实现方式 | 技术栈 | 动态脱敏 | 静态脱敏 | 配置/规则 | 优势 | 局限/问题 |
|---|---|---|---|---|---|---|---|
| postgresql_anonymizer (Dalibo 官方扩展) | 数据库扩展 (anon),在库内实现,支持 RLS 策略、掩码函数 |
Rust (pgrx, v2.0 起) + SQL/PLpgSQL | ✅ 支持(基于角色动态屏蔽) | ✅ 支持(一次性匿名化或导出) | SQL 语法声明(CREATE MASKING POLICY)、DDL 策略 |
官方维护,功能最全;可在查询时自动隐藏,支持 GDPR 合规 | 需在实例安装扩展,部署复杂;托管 PG 云环境可能不允许 |
| pg-anonymizer (rap2hpoutre) | CLI 工具,调用 pg_dump 并在导出时替换敏感列 |
Node.js (faker.js) | ❌ | ✅(生成已脱敏 dump) | 命令行参数 --columns,支持 schema.table.column |
轻量,无需扩展;适合一次性导出脱敏数据 | 仅静态;对复杂 schema 支持有限;需手动维护列清单 |
| pganonymize (rheinwerk-verlag) | CLI 工具,直接连库执行 UPDATE/TRUNCATE,基于 YAML 配置 | Python (Faker) | ❌ | ✅(批量清洗数据库) | YAML 文件(表/列 → provider) | 支持 Faker,能生成逼真数据;配置驱动,适合大规模测试数据 | 破坏性修改数据库;对非 public schema、大小写列名支持差(已知 bug) |
| pganonymizer (arkhn 等) | CLI 工具,YAML 规则 + Faker,结合 pg_dump 脱敏 |
Python | ❌ | ✅ | YAML 文件,规则较丰富 | 偏 GDPR 场景;Faker 支持强;可结合数据导出 | 错误提示不明显,遇到问题容易“静默失败”;对复杂 schema 不够稳定 |
小结
要动态脱敏(生产库角色区分显示) → postgresql_anonymizer(扩展方式,最强大)
要一次性轻量脱敏导出 → pg-anonymizer(Node.js 工具,简单直接)
要批量清洗并生成逼真测试数据 → pganonymize / pganonymizer(Python + Faker,YAML 配置灵活)
参考
https://github.com/rap2hpoutre/pg-anonymizer
https://github.com/asgeirrr/pgantomizer
https://github.com/rheinwerk-verlag/pganonymize