
前言
在分析数据库性能问题的时候,笔者尤其钟爱负载这个指标,负载是”需求”与”能力”之间的直接差值,它横跨 CPU 与 I/O,两类瓶颈一眼可见,笔者在分析数据库性能问题的时候,往往第一时间都先瞅瞅这个指标,再做后续判断。这篇文章中,让我们聊聊负载那些事儿。
系统负载
以 https://www.scoutapm.com/blog/understanding-load-averages 为例,作者将负载定义为 run-queue length:即当前处于 Running 状态 + D(不可中断 I/O) 状态的进程总数,不可中断休眠状态的进程一般是在等待 I/O 完成的进程,也就是说,它同时覆盖了 CPU 和阻塞 I/O 的排队情况。因此,不妨将系统负载看做是真实并发压力的体温计,负载既能做容量红线,又能做性能诊断入口,堪称是数据库运维的 MVP 指标。在此文中,作者用”包含一车道的大桥”的交通比喻解释数值含义:
- 0.00 – 1.00 ⇒ 桥面不排队;
- 1.00 ⇒ 刚好满载;
- 1.00 ⇒ 开始排队,2.00 表示一条车道正行驶、一条车道在等,依此类推。
系统负荷为 1.7,意味着车辆太多了,大桥已经被占满了 (100%),后面等着上桥的车辆为桥面车辆的 70%。以此类推,系统负荷 2.0,意味着等待上桥的车辆与桥面的车辆一样多;系统负荷 3.0,意味着等待上桥的车辆是桥面车辆的 2 倍。总之,当系统负荷大于 1,后面的车辆就必须等待了;系统负荷越大,过桥就必须等得越久。
在实际生产系统中,一般不建议系统满负荷运行。通用的经验法则是:平均负载 = 0.7 * CPU 逻辑核数
- 0.70:长期高于此值就值得关注;
- 1.00:持续超过 1 应立即排查,否则很快就会告警;
- 5.00:意味着系统可能已极度卡顿,需要立刻介入,紧急处理。
横截面趋势
除了关注自身负载之外,”负载趋势”也显得尤为重要,瞬时负载告诉你”现在疼不疼”,而负载趋势告诉你”病是怎么得的、会不会复发”。
- 如果 load1 > load5 > load15,说明刚刚进入拥塞,查询/IO 正在排队,这个时候就需要立即采取动作,望闻问切,如果是高峰时段,可短暂扩容或快速限流。
- 如果 load1 < load5 < load15,说明负载消退中,可能是峰值过去、批量任务结束或索引命中率恢复,我们需要关注是否有残留锁、慢 VACUUM、慢查询等尾巴,避免再次反弹。
- 另外也别忽视”负加速度”:如果 load1 < 0.5 × load5,可能是故障恢复后流量骤降
- 若 load15 长期高而 CPU% 不高,多半是 I/O 慢或锁争用;优化难度往往更高,需要结构性调优,比如索引、建模、硬件升级等
历史趋势:从曲线读出故事
- 日周期锯齿,可能原因是固定批量任务 / 报表 / 备份,可以将批量作业移到离峰,加并行或分区
- 周末平坦,而周一陡升,意味着周末流量低、缓存冷,可以热备预热、增加自动伸缩冷启动窗口
- 如果基线缓慢抬高,意味着平均访问增多,新功能上线、数据集增大,我们可以重新对当前集群算力进行预估,跑基准验证新版本 SQL
- 忽高忽低”锯齿”,这种就相对要麻烦一些,判断是否有锁竞争、IO 突刺 (比如 checkpoint、freeze 风暴、索引失效等)
只有把 load 1/5/15 的加速度和历史曲线一起纳入监控,才能做到既能早预警、又能追根溯源,把数据库性能问题扼杀在萌芽阶段。
瑞士军刀 sar -q
又看到我们的老朋友了,是的,又是它 sar。前面介绍了使用 sar 分析网络丢包排障的文章,sar 观察负载也是一把好手
1 | [postgres@mypg ~]$ sar -q 1 |
Run Queue Size —— 当前处于 R 状态的任务数
Process List Size —— 系统进程 (线程) 总数
blocked —— 当前处于 D 状态 (不可中断,等待 I/O 完成) 的任务数, 值大表明正在卡磁盘 / 网络 / NFS / 复制;常与 iostat %util & await 一起看
数据库负载
前面聊完了系统负载,那么关于数据库,如何去衡量”负载”这个指标呢?操作系统和数据库毕竟是分开的,数据库跑在操作系统之上,严格来说它们是系统的指标,而非数据库软件自身的指标,数据库自身也可能因为各种原因出幺蛾子。
因此,回到数据库自身,是否有类似的负载指标?很可惜,原生 PostgreSQL 并没有类似这样的指标,但是我们知道,一些 CLI 工具是包含 LOAD 这个指标的,比如 pg_top、pg_activity、pg_views 等等。以 pg_top 为例:
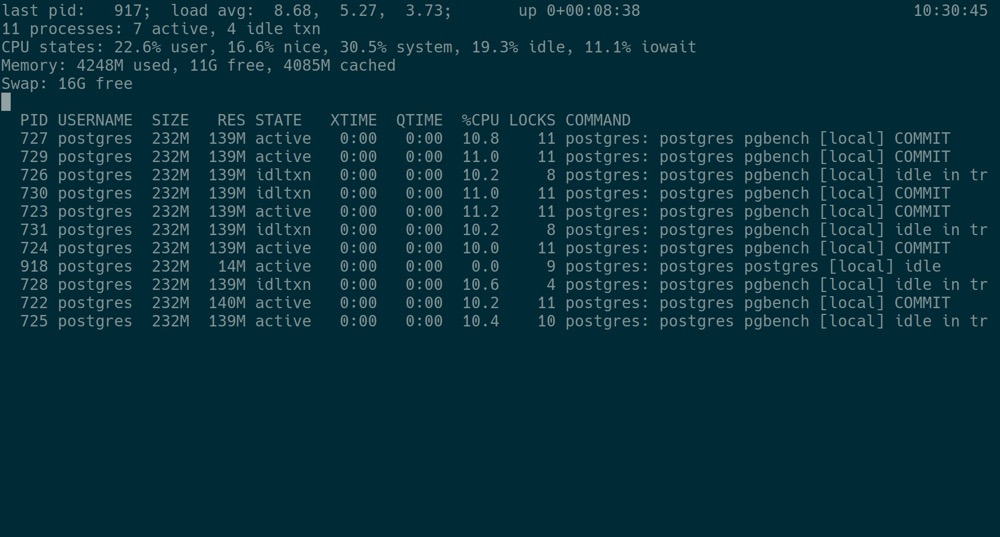
那么这个 load 是如何计算出来的呢?可惜的是,pg_top 本身 从不计算 负载,只负责”搬运 + 排版”。
1 | void |
而对于远程模式,获取源端机器的负载,则借助于 pg_proctab 插件,同样也是取自 OS,其提供了如下几个函数:
- pg_cputime
- pg_loadavg
- pg_memusage
- pg_proctab
因此,严格来说,数据库的负载需要我们去自行计算,感兴趣的童鞋可以参照冯董的文章 PostgreSQL 的 KPI。
小结
负载是个好指标 👍🏻
参考
https://www.scoutapm.com/blog/understanding-load-averages
http://jartto.wang/2020/01/20/system-load/
https://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html