
前言
最近天天和网络问题打交道,什么重传、丢包、IP 重组失败等等,之前曾写过一篇 DBA 必备技能之网络丢包分析总结,聊了一下丢包的种种原因,丢包会涉及到⽹卡、驱动、内核协议栈三⼤类,每一层都有可能会丢包,有可能是驱动层,有可能是协议层,也有可能是硬件层等等,今天这一期简单总结下分析网络问题的瑞士军刀 —— sar,用好轮子可以让我们事半功倍。
sar
sar (System Activity Reporter) 号称为最为全面的系统性能分析工具之一,以前在分析内存问题的时候也经常使用,除此之外,还支持查看 IO、CPU、文件系统等等,不仅如此,sar 还是分析网络问题的一把好手:
- 怀疑 CPU 存在瓶颈,可用 sar -u 和 sar -q 等来查看
- 怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
- 怀疑 I/O 存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
- 怀疑网络有问题,可用 sar -n 来查看
sar -n 支持很多子选项,加上关键字 “E” 则是查看 ERROR,比如 sar -n DEV 用于查看网络接口统计信息,那么 sar -n EDEV 则是查看网络接口错误,同理,sar -n IP 用于查看 IP 数据报统计信息,sar -n EIP 则是用于查看 IP 错误统计信息,以此类推。
sar -n EDEV
用于快速判断网卡层是否存在硬件故障、丢帧、FIFO 溢出等问题,可以使用 sar -n EDEV 1 | awk ‘NR == 3 || $3 == “xxx” || $3 == “xxx”‘ 仅观测关心的网卡情况:
- rxerr/s:每秒接收出错的报文总数
- txerr/s:每秒发送出错的报文总数
- coll/s:每秒以太网碰撞次数
- rxdrop/s:每秒因内核缓冲区不足丢弃的接收报文数
- txdrop/s:每秒因缓冲区不足丢弃的发送报文数
- txcarr/s:每秒发送载波错误数 (常见于线缆/PHY 问题)
- rxfram/s:每秒接收帧对齐错误数
- rxfifo/s:每秒接收 FIFO 溢出次数
- txfifo/s:每秒发送 FIFO 溢出次数
sar -n EIP
用于判断 IP 层是否因地址配置/转发策略错误或缓冲区不足造成丢包。对于 IP 层,以 Greenplum 为例,主要关注 IP 重组失败:
对于 IP 分片,数据帧不是无限大的,数据帧长度受到 MTU 限制,由于应用层数据有的时候会超过 MTU,超过了链路层的最大运输能力,因此需要对数据进行分片传输。TCP 有着自己的分片规则,但是 UDP 没有实现对应的分片,每次都是按照报文传输,不论报文多大。所以这就苦了 IP 层,IP 层会对 UDP 数据包进行分片传输。并且如果在传输过程中,一次传输被分成多个分片,传输中有一个小分片丢失,那接收端最终会舍弃整个文件,导致传输失败,这就是 UDP 不可靠的原因。而 TCP 的话,MTU 通过限制 MSS (单个数据报的最大消息长度) 的取值,来限制单个 TCP 包的长度。
由于分片可能因丢包而永远无法到达,分片重组必须有超时机制。如果重组无法在一定时间内完成,系统将删除缓冲区中的碎片,放弃重组。因此,如果有分片因路由延迟到达不及时,重组也会失败。另外,系统用于分片重组的内存是有限的,当大量分片达到导致缓冲区不够用时,系统也会放弃重组,巨帧的好处体现出来了。如下这几个参数用于控制这些行为:
- net.ipv4.ipfrag_high_thresh:设置了碎片缓冲区的高水位线为 4194304 字节 (4 MB)。当碎片缓冲区的使用率超过该阈值时,内核会开始丢弃新到达的碎片。
- net.ipv4.ipfrag_low_thresh:设置了碎片缓冲区的低水位线为 3145728 字节 (3 MB)。当碎片缓冲区的使用率低于该阈值时,内核会停止丢弃新到达的碎片。
- net.ipv4.ipfrag_max_dist:是一个用于限制数据包分片重组的内核参数。它定义了分片偏移 (fragment offset) 之间的最大允许间隔。当分片之间的偏移超过此阈值时,内核会丢弃分片并阻止重组,以防止可能的攻击和资源耗尽。
- net.ipv4.ipfrag_time:设置了碎片在缓冲区中保持的时间为 30 秒。超过该时间的碎片将被丢弃。
sar -n 提供如下指标,着重关注 asmf 和 fragf。
- ihdrerr/s:每秒因 IP 报文头错误(校验和、版本号、TTL 超时等)被丢弃的输入报文数
- iadrerr/s:每秒因目标地址非法而被丢弃的输入报文数
- iukwnpr/s:每秒因上层协议未知/不支持而丢弃的本机定向报文数
- idisc/s:每秒由于资源不足等原因被丢弃的输入报文数 (无错误但被丢)
- odisc/s:每秒由于资源不足被丢弃的输出报文数
- onort/s:每秒因为“无路由”而被丢弃的输出报文数
- asmf/s:每秒 IP 重组失败次数
- fragf/s:每秒因不可分片(DF 位)而丢弃的报文数
sar -n ETCP
ETCP 则是用于定位重传高、RST 异常、握手失败等问题,常与抓包/ss 结合分析。
- atmptf/s:每秒 TCP 连接建立尝试失败次数(SYN‑SENT/RCVD→CLOSED/ LISTEN)
- estres/s:每秒已建立连接被复位而直接关闭的次数
- retrans/s:每秒重传的 TCP 段数(衡量网络重传比例的重要指标)
- isegerr/s:每秒收到的 TCP 差错段数(如校验和错误)
- orsts/s:每秒发送的带 RST 标志的 TCP 段数
retrans 是一个很重要的指标,常见原因是线路丢包、驱动/软中断丢包、拥塞窗口过小、内核/网卡 Buffer 不足,会导致吞吐下降、查询延迟抖动。我们可以调整 ring buffer 大小 (ethtool -G),提升网卡队列深度 (ethtool -L)、提升Socket Buffer & 拥塞控制等 (tcp_mem*,socket_buffer)。下面这个图一目了然:
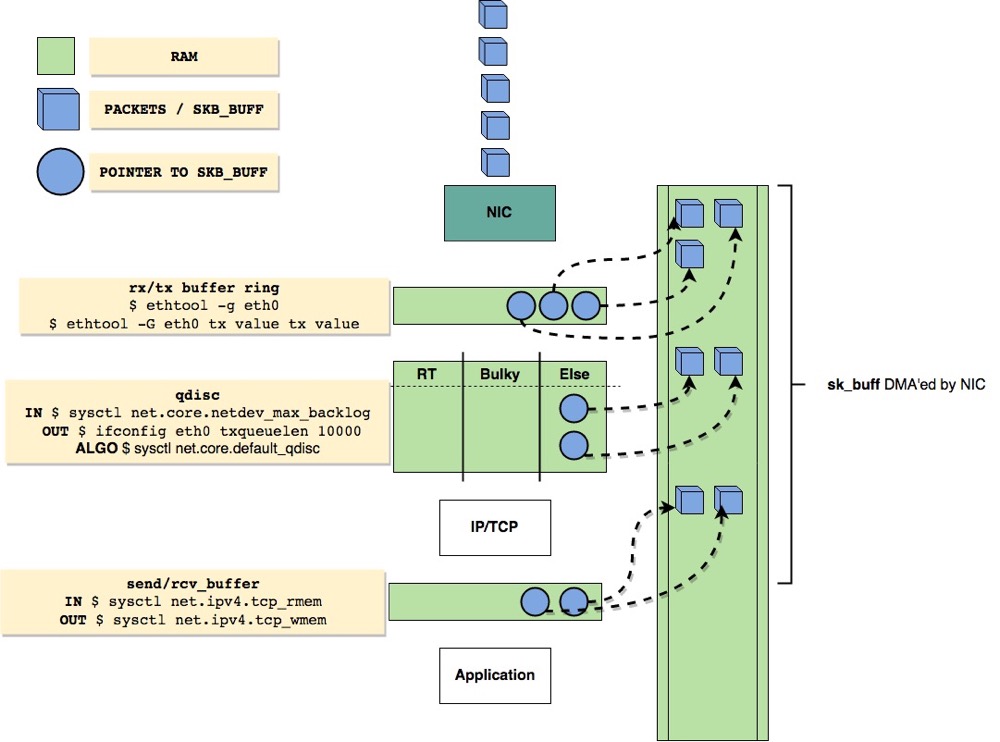
ring buffer:吸收突发流量,防止驱动层丢包;太大会占内存、增加时延,网卡在收到包后会将帧存放在硬件的 frame buffer 上,并通过 DMA 同步到内核的一块内存,这就是 ring buffer
硬 IRQ 合并:降低 IRQ 频率、减轻 CPU,中高吞吐场景常调,在最传统的中断模式下,每个帧将产生一次硬中断,CPU 0 收到硬中断后产生一个软中断,内核切换上下文进行协议栈的处理
软 IRQ & Ingress Qdisc:控制 NAPI 一次能拉多少包、Input 排队深度,关键参数:netdev_max_backlog,NAPI 是一种更先进的处理方式
Egress Qdisc,Output 队列长度 + 算法;与 Bufferbloat、流控息息相关,关键参数:txqueuelen + net.core.default_qdisc,txqueuelen 用于增大网卡传送队列的长度,表示最大缓存包的数量,超过这个数量的包会被丢弃,Socket → Qdisc 由 net.core.default_qdisc 控制,Qdisc → Driver 是设备发送队列 (txqueuelen),设备层的软件发送队列长度 (包数)。当 Qdisc 把包送到驱动,如驱动/硬件忙,包会在此排队。

TCP Buffer:决定单连接窗口大小与拥塞控制可扩展范围,关键参数:net.ipv4.tcp_rmem + net.core.rmem_max,tcp_rmem 和 tcp_wmem 是 TCP 专用三元组,决定 TCP 自动调优在单个连接内能把窗口扩到多大,但实际可扩大的最大值不能超过 net.core.*mem_max,这俩参数是天花板。关于 socket 缓存,强烈推荐这篇文章 👉🏻 Socket 缓存究竟如何影响 TCP 的性能?
监听 & 拥塞:受 RST、SYN 拒绝、TIME_WAIT 暴涨等场景影响,关键参数:net.core.somaxconn + tcp_max_syn_backlog,somaxconn 是三次握手完成后的 Accept 队列天花板,tcp_max_syn_backlog 控制还在握手的 SYN_RECV 队列长度
小结
网络是一个庞大的子系统,尤其对于分布式数据库,网络又是一项关键的组件,对于我们每位 DBA 来说,学习与掌握好网络是必备技能之一。下一期,再聊聊常见的网络调优技能。
参考
https://www.ryanchan.top/archives/linux-kernel-and-network-tuning-guide
https://www.starduster.me/2020/03/02/linux-network-tuning-kernel-parameter/