
前言
昨天某位客户的集群,在执行 SQL 的时候,突然大量提示如下错误:
ERROR: Interconnect encountered a network error, please check your network.
这个报错信息看似很明显,与网络有关,但是网络幺蛾子千奇百怪,丢包、乱序之类的,借此机会,好好学习下 Greenplum 中的 interconnect,要想学好 Greenplum,网络必须得掌握啊。
架构
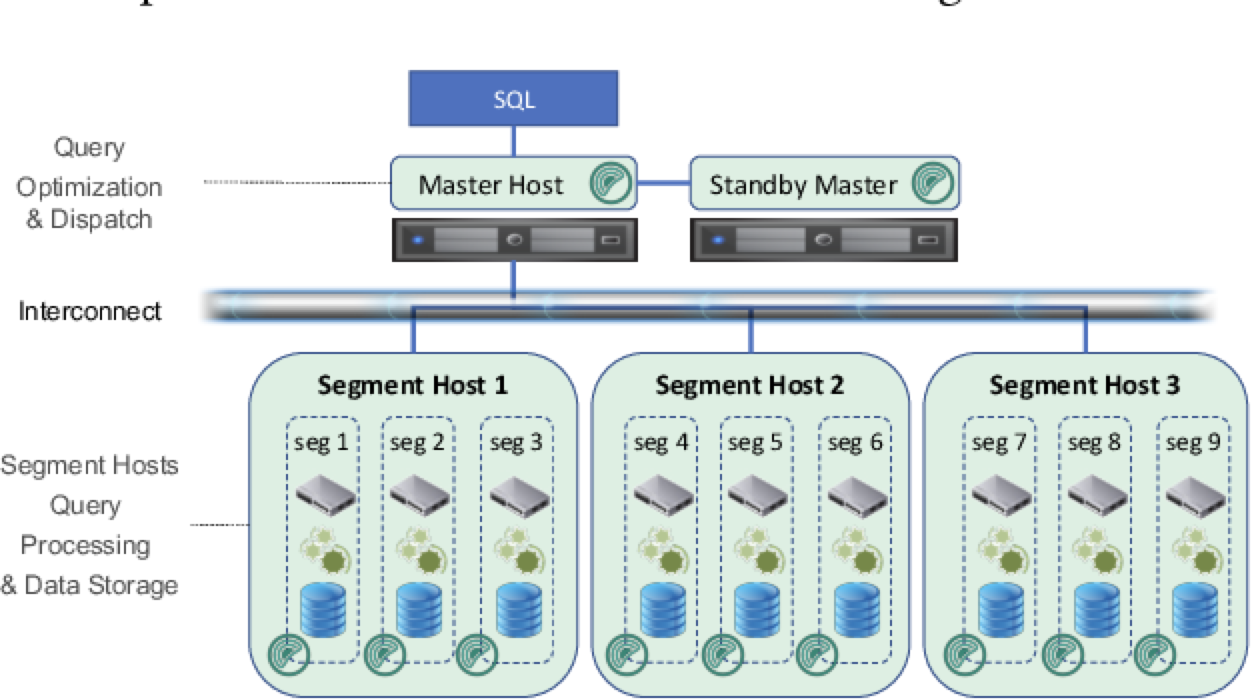
在介绍之前,先回顾一下 Greenplum 的整体架构:
- master 节点主要存储元数据,负责执行计划的生成与查询接入
- segment 节点即计算节点,负责存储实际数据的存储以及分布式执行计划的执行
- interconnect network,高速内联网络,主要用于集群间的通信与数据重分布
像 QD (query dispatcher,主节点) 和 QE (query executor,计算节点),QE 和 QE 之间的表元组数据传输均是通过 interconnect 实现的。
The full name of QD is query dispatcher, which is a distributor, while QE is query executor, which processes queries. All QD and QE processes will work together to complete the query request sent by the client.
目前有两种 interconnect 实现方式,一种基于 TCP,一种基于 UDP。相较于 TCP,UDP 占用的端口要少得多,其次从性能上也会更好,因此默认情况下,Greenplum 使用的是 udpifc,在 UDP 的基础之上加入了 ACK、重传等机制来实现了一种可靠有序的数据传输。
TCP 是一种点对点的有连接传输协议,一个有 N 个 QE 节点的 Motion 的连接数是 N^2,一个有 k 个 Motion 的查询将产生 k*N^2 个连接。
举例来讲,如果一个包含 500 个 Segment 的集群,运行一个包含 10 个 Motion 的查询,那么这个查询就需要建立 10*500^2 = 2,500,000 个TCP连接。即使不考虑最大连接数限制,建立如此多的TCP 连接也是非常低效的。
简单来说, 对于一个具有 m 个 slice 的查询, 当其运行在具有 n 个计算节点的集群上时, 每一个计算节点都需要占用
n * m个端口. 在实际生产中, m 一般取值为 100, n 一般取值为 64, 也即用户 1 条查询, 一个计算节点就需要占用 6400 个端口, 也即最多只能支持 10 并发
1 | postgres=# show gp_interconnect_type ; |
关于 Interconnect 模块的内核原理,可以去听一下 PostgreSQL 技术内幕(五)Greenplum-Interconnect模块
IP 分片
我们知道,对于网络协议,每一层都有自己的功能,各司其职,就像建筑物一样,每一层都靠下一层支持,每一层传输单位都有不同的名词,数据链路层的传输单位是帧,IP 层的传输单位是包,TCP 层的传输单位是段,HTTP 的传输单位则是消息或报文,都可以简称为数据包。
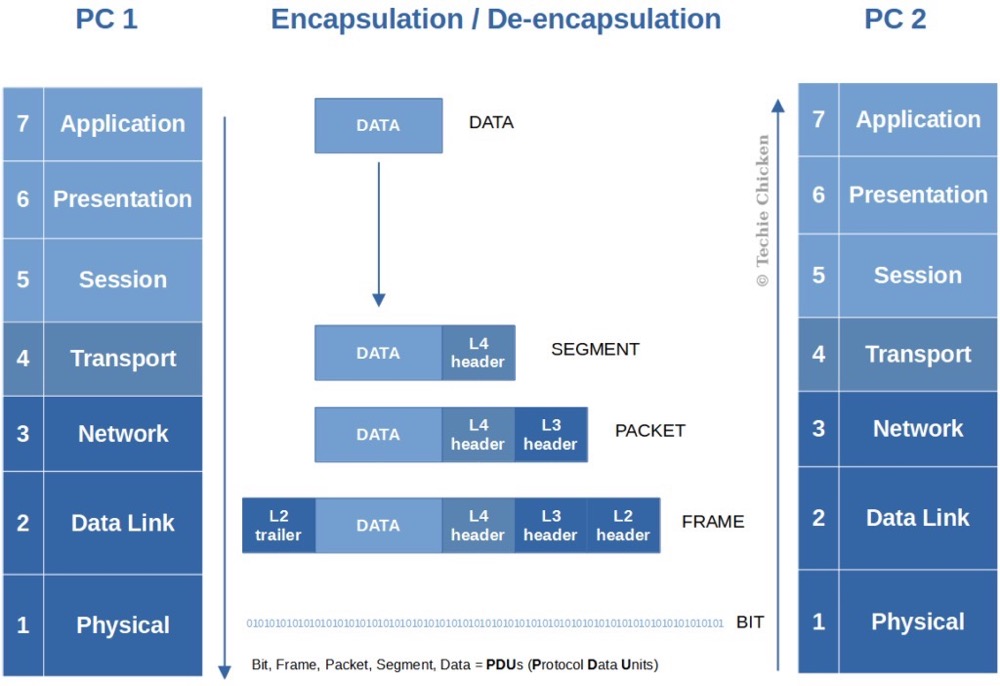
数据帧不是无限大的,数据帧长度受到 MTU 限制,由于应用层数据有的时候会超过 MTU,超过了链路层的最大运输能力,因此需要对数据进行分片传输。TCP 有着自己的分片规则,但是 UDP 没有实现对应的分片,每次都是按照报文传输,不论报文多大。所以这就苦了 IP 层,IP 层会对 UDP 数据包进行分片传输。并且如果在传输过程中,一次传输被分成多个分片,传输中有一个小分片丢失,那接收端最终会舍弃整个文件,导致传输失败,这就是 UDP 不可靠的原因。而 TCP 的话,MTU 通过限制 MSS (单个数据报的最大消息长度) 的取值,来限制单个 TCP 包的长度。Greenplum 对 UDP 这块进行了增强,实现了可靠传输。
由于分片可能因丢包而永远无法到达,分片重组必须有超时机制。如果重组无法在一定时间内完成,系统将删除缓冲区中的碎片,放弃重组。因此,如果有分片因路由延迟到达不及时,重组也会失败。另外,系统用于分片重组的内存是有限的,当大量分片达到导致缓冲区不够用时,系统也会放弃重组。如下这几个参数用于控制这些行为:
net.ipv4.ipfrag_high_thresh设置了碎片缓冲区的高水位线为 4194304 字节 (4 MB)。当碎片缓冲区的使用率超过该阈值时,内核会开始丢弃新到达的碎片。net.ipv4.ipfrag_low_thresh设置了碎片缓冲区的低水位线为 3145728 字节 (3 MB)。当碎片缓冲区的使用率低于该阈值时,内核会停止丢弃新到达的碎片。net.ipv4.ipfrag_max_dist是一个用于限制数据包分片重组的内核参数。它定义了分片偏移 (fragment offset) 之间的最大允许间隔。当分片之间的偏移超过此阈值时,内核会丢弃分片并阻止重组,以防止可能的攻击和资源耗尽。net.ipv4.ipfrag_time设置了碎片在缓冲区中保持的时间为 30 秒。超过该时间的碎片将被丢弃。
解析
有了前面的前置知识之后,让我们再分析下这个报错。本地先构造一个较大的数据:
1 | postgres=# create table bytea_test(data bytea); |
然后基于会话 ID,获取到进程号之后,再用 strace 观察一下,strace -ttt -T -p xxx。当我执行 select * from bytea_test 之后,可以看到 sendto 函数发送了很多条 8192 长度的数据
1 | 1721371014.485835 sendto(10, "87878787878787878787878787878787"..., 8192, 0, NULL, 0) = 8192 <0.000087> |
而这个 8192 的大小由 gp_max_packet_size 参数控制。
1 | postgres=# show gp_max_packet_size ; |
我本地网卡的 MTU 都是 1500,因此,IP 层便需要对这些数据进行分片,这些分片被发出去后,独立在网络中旅行,可能走不同的路由路径,到达时间和顺序也是无法预测的,这一点我们可以通过 traceroute 来分析,用于追踪数据包在网络上的传输时的全部路径。
为了确认进行了分包,我们可以使用 tcpdump + wireshark 分析一下,此处就应用最简单的过滤规则
1 | sudo tcpdump -i eth0 'ip' -w capture.pcap |
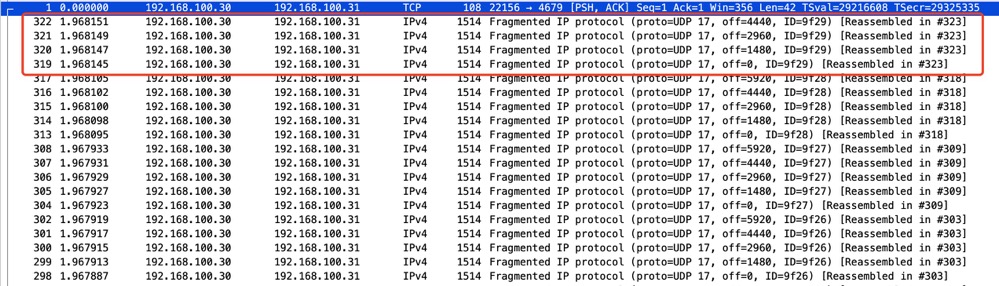
这些抓取的分片数据包表明有较大的 UDP 数据包通过网络传输,并由于超过了 MTU,被 IP 层分片传输 (Fragmented IP protocal)。offset 表示这是 IP 分片,不同的分片具有不同的偏移量,接收端根据此属性的顺序重组切片。而我们看到的 1514 字节则是 MTU + 以太网帧头 (通常是 14 字节) 的大小。
那么为什么昨天客户环境会报大量的 ERROR: Interconnect encountered a network error, please check your network.? 原来在昨天上午,集群中有一个计算节点主机异常重启了,重启之后,网卡的 MTU 变成了 1500,而发送端的 MTU 是 8500,而 Greenplum 默认的报文大小是 8KB,没有分片。因此,接收端由于发送包的大小超过了自身 MTU (1500) 而丢弃。
让我们验证一下,修改其中一个计算节点的 MTU
1 | [root@master1 ~]# ifconfig ens192 | grep mtu |
然后再次执行查询便可以成功复现了:
1 | postgres=# select * from bytea_test ; |
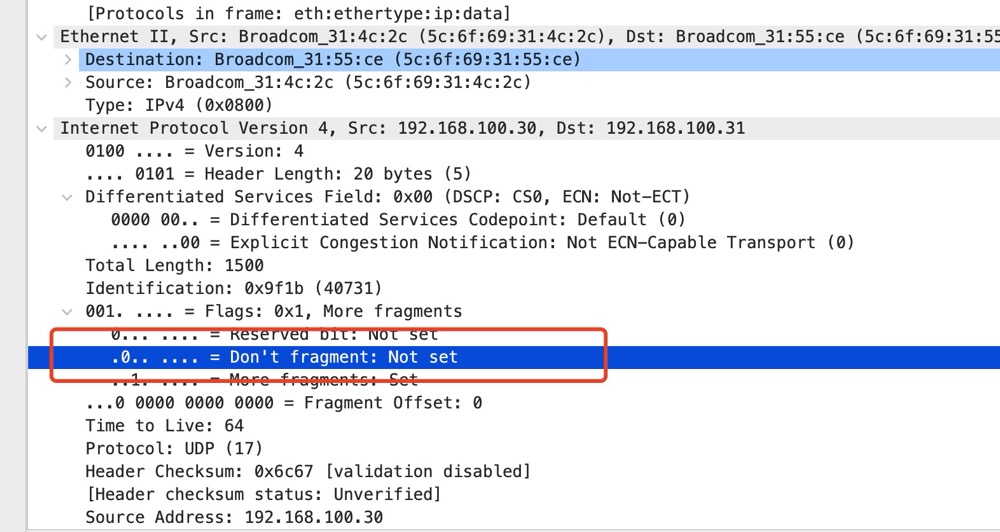
用 ping 也同样可以验证,当达到 2000 的时候,便再也 ping 不通了。而 TCP 的话,建立 TCP 连接的两端在三次握手时便会协商 MSS 的大小,协商双方会比较syn 和 syn+ack 报文中 MSS 字段大小,选择较小的 MSS 作为发送 TCP 分片的大小,那到了链路层肯定也是小于 MTU 的,这样就不必在网络层进行分片了。MTU - (TCP 标头 + IP 标头) = MSS 。UDP 不会分段,就由 IP 来分。TCP 会分段,当然就不用 IP 来分了,因此,udpifc 很依赖 IP 分片这个特性。
之前抓取的报文中也可以看到,Don’t fragment 并没有设置,即允许分片。
知晓了原因,解决办法也很简单,调整 MTU,或者调整 gp_max_packet_size ,降低到 MTU,一般 1500 以下,比如 1400。
小结
让我们复盘一下此次案例:
- 集群某个计算节点主机异常重启,导致网卡的 MTU 变成了默认的 1500
- Greenplum 默认的报文大小是 8KB,由 gp_max_packet_size 控制
- 发送端网卡的 MTU 是 8500,而接收端是 1500,sender 发送了 8KB 的数据,小于 MTU,因此 IP 层没有分片,直接把 8KB 数据全部发了过去
- 超过了接收端的最大传输单元 MTU,IP 层组包发生错误,那么包就会被丢弃。接收方无法重组数据报,将导致丢弃整个 IP 数据报。
MTU 的通用处理思路:逐段 ping 大包测试。大包长度分别为大于、小于、等于接口 MTU 值。如果 ping 长度大于接口 MTU 时不通,小于等于接口 MTU 时能通,可初步认为是 MTU 问题。
还有些网络的知识模棱两可,后续再慢慢恶补吧。
参考
PostgreSQL 技术内幕(五)Greenplum-Interconnect模块
https://segmentfault.com/q/1010000007862841
https://blog.csdn.net/qq_43684922/article/details/129460287
https://blog.csdn.net/LearnLHC/article/details/115228649