
前言
在一些前沿数据库中,都可以看到一个很火的词汇——向量化执行引擎,比如 ClickHouse、DuckDB、Doris 等等,我对这个概念一直都停留在浅显的理论层面,一直没有机会深入,借此机会,好好捋一捋这个高大尚的词汇。
传统数据库执行器
早期数据库受限于硬件,内存和 CPU 等都十分昂贵,所以大多数数据库执行器都采用传统的火山模型,火山模型又称 Volcano Model 或者 Pipeline Model,火山模型从最顶层的输出节点开始,不断从下层节点拉取数据,一种自顶向下的执行方式,所以也可以称之为拉取模型。最常见的拉模型是 Tuple-At-A-Time,即每次从下层拉取一个元组,这样可以缩减内存使用量,但是这样的话,CPU 的大部分处理时不是用来真正的处理数据,而是在遍历查询操作树,CPU 有效利用率不高,同时这也会导致低指令缓存性能和频繁跳转。在火山模型中,一个查询计划会被分解为多个代数运算符 (Operator)。每个 Operator 就是一个迭代器,都要实现一个 next() 接口,通常包括三个步骤:
- 调用子节点 Operator 的 next() ,获取一个元组
- 对元组执行 Operator 特定的处理;
- 返回处理后的元组。
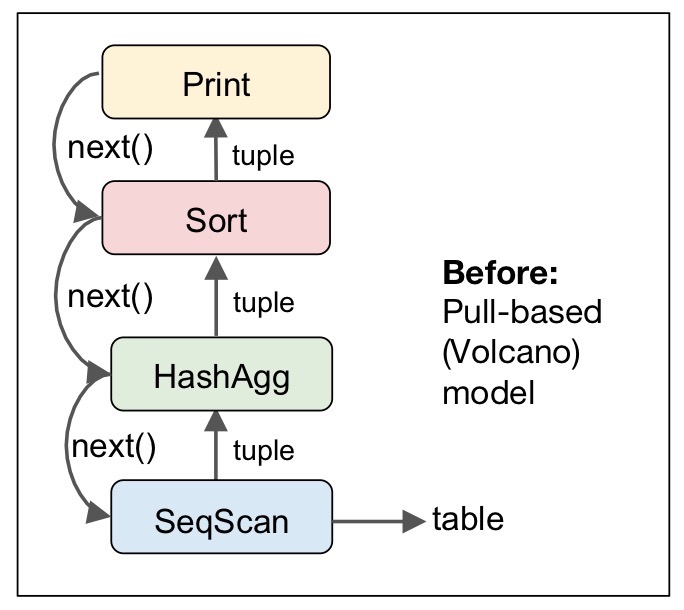
以 PostgreSQL 为例:

可以看到,查询树每次调用 next() 接口从下层节点拉取一条元组,自顶向下嵌套调用 next() ,数据则自底向上地被拉取处理,Joins、Order By 等操作经常会阻塞。
但是为什么之前的数据库设计者没有去优化这方面呢?是他们没想到吗?怎么可能?这个时候我们可能要考虑到 30 年前的硬件水平了,当时的 IO 速度是远远小于 CPU 的计算速度的,那么 SQL 查询引擎的优化则会被 IO 开销所遮蔽(毕竟花费很多精力只带来 1% 场景下的速度提升意义并不大)。
随着硬件的不断革新,硬件的能力早已不同往日,火山模型的弊端逐渐显露。性能表现差强人意。当需要处理的数据量增大时,具有显著的缺陷。搞懂了火山模型的缺点之后,现在来讲为什么向量化模型能够解决这个问题。鉴于火山模型每次处理一行一行数据,next 调用代价又比较高,那么我们可以很自然地想到,**有没有办法一次处理一批数据呢?**这正是向量化模型的重要区别,每个 operator 仍然需要实现 next() 函数,但是每次调用 next() 函数返回的是一批元组,而不是一个元组,所以向量化模型也可称为批处理模型。
在提及向量化模型之前,我们还需要了解一下列存的概念,以及为什么向量化执行引擎必须要构架在列存储的表上才能够发挥出最大的优势,列存之于向量化引擎,就好比王八看绿豆——看对眼了。列存,顾名思义,按照列进行存储,一列数据存储在一起
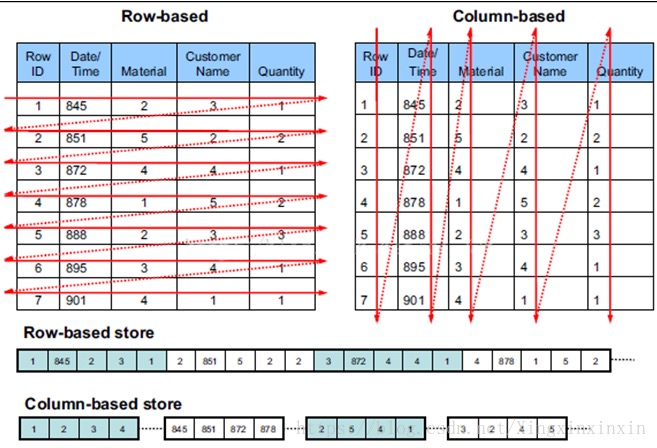
这样的好处不言而喻,这样类似的数据在进行压缩的时候,能够达到一个比较好的压缩比,其次按列读取,相对于行存将所有数据读取上来再提取对应的属性,可以减少 I/O 总量。另外因为列存每列的各行数据存储在一起,可以认为这些数据是以数组的方式存储的,基于这样的特征,当该列数据需要进行某一同样操作 (做到取多条数据同时计算),可以使用 SIMD 进一步提升计算效率,SIMD的全称是:Single Instruction Multiple Data,在一条指令中同时处理多个数据的技术叫做 SIMD。SIMD 指令在本质上非常类似一个向量处理器,可对控制器上的一组数据 (又称“数据向量”) 同时分别执行相同的操作从而实现空间上的并行。
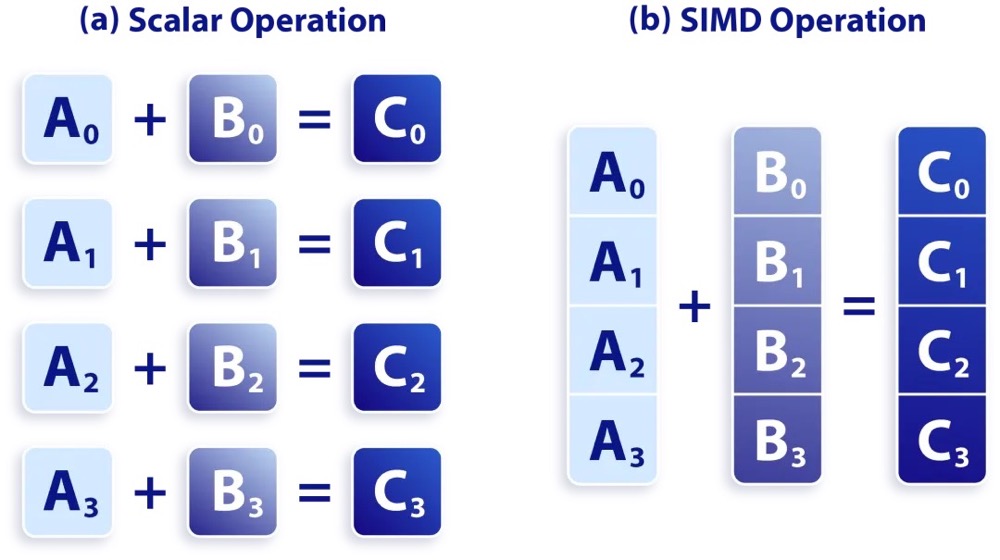
如上图所示:
- 一个普通加法指令,一次只能对两个数执行一个加法操作。
- 一个 SIMD 加法指令,一次可以对两个数组 (向量) 执行加法操作。
经过多年的发展,支持 SIMD 的指令集有很多。各种 CPU 架构都提供各自的 SIMD 指令集,要判断当前设备 CPU 的支持能力,在命令行通过 cat /proc/cpuinfo 在输出中查看 flags 一项,看是否包含 avx、avx2 等。SIMD 指令需要硬件支持 MMX 系列,SSE (Streaming SIMD Extensions) 系列、AVX (Advanced Vector Extensions) 系列扩展指令集。目前大部分 CPU 都支持 AVX2,只有最新的 CPU 才支持 AVX512。
因此,向量化执行引擎就采用了这种思路,每次处理一批数据。向量化执行引擎能够发挥效率的前提是数据是按列存储的,基于行存模型去谈向量化是不可能的。对于典型的 OLTP 点查场景,行存则更有优势。另外还有一种优化方式是采用 Push 模型,从最底层的节点起始,持续生成数据,并逐级将数据推送给上层节点。
一般来说,每个处理节点都有两个通道,一个入口,负责接收子节点的数据;一个出口,负责输出给上层节点处理后的值。
那么每个处理节点(父子节点),都可以看做是一个生产者消费者模型。
对于消费者而言,有两种方式获取信息:
- 推模型 (push):由消息中间件主动将消息推送给消费者;可以尽可能快地将消息发送给消费者,但是若消费者的处理消息的能力较弱(一条消息长时间处理),中间件会不断地向消费者 push 消息,消费者的缓冲区可能会溢出;
- 拉模型 (pull):由消费者主动向消息中间件拉取消息;会增加消息的延迟,即消息到达消费者的时间变长。
推模型比拉模型复杂,但 CPU 利用率要高于拉模型。由于子算子产生的结果会直接 Push 给父算子进行操作,Push 模型的 Context switch 相对较少,对 CPU Cache 的友好性也更强。但是使用推模型会不可避免的产生其他问题。如果使用拉模型,那么使用一个进程就可以完成整个 SQL 的执行流程;但是换成推模型,每个节点都会自发运行往父节点推数据,那么一个 SQL 就需要使用多个进程来完成,CPU 的利用率肯定是上去了,但是如果存在高并发场景,并发执行 SQL 量很多,那么进程数也会暴增。
小结
- 火山模型,可以很容易实现输出控制,比如 limit 返回 TopN 的时候,虽然被称为流水线方式,但是某些算子是会阻塞流水线的,也就是需要等到子节点完成所有数据的处理后才能继续运转,比如我们所熟知的 ORDER BY,子查询等。另外火山模型处理逻辑清晰,每个Operator 只要关心自己的处理逻辑即可,耦合性低。
- 向量化模型,通常用在 OLAP 数仓类系统,结合 SIMD,一次性处理一批数据,可以显著提高查询的执行效率。

甚好,经过学习,对这些概念有了一些更加清晰的认知。
参考
【CMU 15-445/645 Database Systems】12 Query Processing - 01A
PgSQL内核特性 - push-based pipeline 执行引擎
PieCloudDB 自研全新向量化执行器,带来性能的数量级提升
https://blog.51cto.com/u_12740336/6105060