
前言
一般我们遇到 SQL 性能问题,手段比较有限,诸如分析执行计划 (PEV),改写 SQL,加索引等等,这些也要求一定的经验与功力。
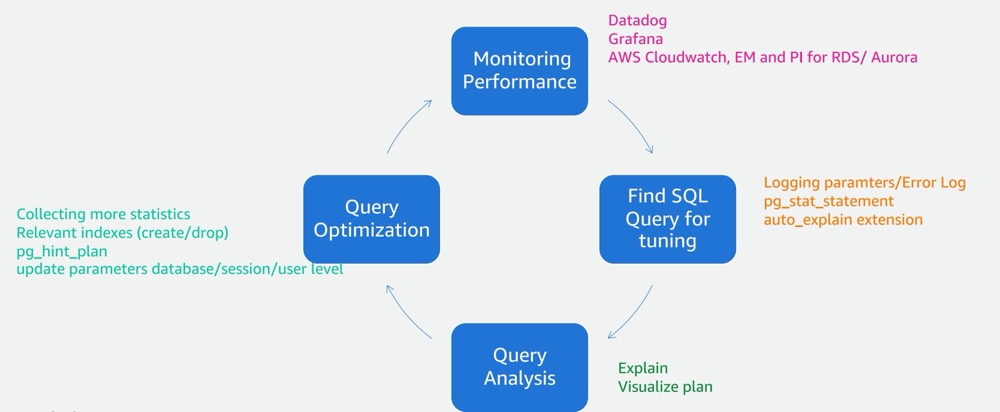
其次作为 DBA,开发也会经常挑战我们,单个 SQL 会消耗多少内存?多少 CPU?不借助额外插件(比如 pg_stat_kcache)的话,我们是无法知晓的。正好最近也一直在捣鼓 SQL 优化相关的事情,今天在学习过程中,又发现了一个十分有价值的 SQL 性能分析工具——ExplainFull,按照当下手机厂商时髦的叫法,不如就取名为 Explain Plus吧。
DSEF
地址在 https://github.com/ardentperf/dsef/,DSEF 的全称是 DiffStats and ExplainFull
DiffStats and ExplainFull can generate detailed reports which are useful for troubleshooting performance of a SQL statement, and especially for working with third parties who are helping in the process. It reduces the amount of back-and-forth requests for information by capturing a great deal of commonly useful data about the performance of a SQL statement.
DiffStats 和ExplainFull 可以生成详细的报告,这些报告对于解决SQL 语句的性能问题非常有用。
安装很简单,1分钟搞定,因为是几个纯文本函数,所以 psql -f 直接导入至数据库中即可。
1 | curl -O https://raw.githubusercontent.com/ardentperf/dsef/main/sql/dsef.sql |
当然你也可以以插件的形式进行安装,此处不再演示。目前 DSEF 暂不支持在备库或者只读库中使用。
另外,如果还有 pg_proctab 插件的话,还可以收集操作系统级别的统计信息,比如 CPU/内存/磁盘等等,和 EDB 的 system_stats 插件类似。
1 | postgres=# \dx+ pg_proctab |
DSEF 还支持收集系统级和会话级的等待事件详情,不过可惜的是,只有在 Aurora 上支持
- If pg_proctab is available, DSEF will use it to include all available Operating System statistics in its report.
- On Aurora, DSEF will include wait event statistics at both the system and session level in its report.
- With appropriate privileges, DSEF can be installed as an extension on self-hosted PostgreSQL and on RDS PosgreSQL 14.5+
小试牛刀
介绍完了之后,让我们实操一下,使用形式很简单,只需要 select * from explain_analyze_full + 实际的查询语句即可,此处我构造了一个两表关联的查询语句,由于内容过长,让我们分开来看
1 | postgres=# select * from explain_analyze_full('SELECT |
前面的内容相当于帮你加上了 EXPLAIN (ANALYZE,VERBOSE,COSTS,BUFFERS,FORMAT TEXT,TIMING,SETTINGS,WAL) ,并且很贴心地给你打印出来了 Query Identifier。后面的内容就比较有价值了,还会将一些关键性的数据,比如 pg_class.reltuples、relpages,MCV、直方图等等都打印出来,其次还会将利用到的索引状态,比如元组数,是否是唯一索引等等,都打印出来,有了 MCV,我们就可以快速判断出这个 SQL 是否可以直接利用 MCV + MCF 计算出选择率。
1 | Table public.enrollments: pages 637, tuples 100000, allvisible 637, kind r |
其次是一些系统级的参数
1 | name | setting | unit | source |
功能到这就结束了吗?NONONO,DSEF 还支持比较同一个 SQL 不同执行计划间资源消耗情况,比如我想对比走索引和不走索引之间的性能差异和资源消耗情况,我该怎么做?借助 ds_capture() 即可。
1 | select ds_start(); |
看个例子 (内容过多,我这里就贴了部分)

可以看到,前后两次的 cnt_diff 都列举了出来,比如 IO 增加了 72%,总时间的差异等等。关于这些性能指标的解读,可以参照 pg_proctab: Accessing System Stats in PostgreSQL,无疑,有了 DSEF,可以大大方便我们对比分析不同的访问路径,而不仅仅只是从一个 Execution time 来对比,给作者打 call!

小结
赶紧用起来吧!SQL 性能诊断利器+1。下一期与各位分享等待事件的诊断利器。