
前言
关于 effective_cache_size 参数许久之前也曾翻译过一篇文章,最近在复核 14 internal 的时候,又有了一些新的理解与感触。
何如
众所周知,在 PostgreSQL 的双缓存架构下,其对于自己的 shared_buffers 有着”绝对”掌控权,但是对于文件系统缓存一无所知,加之 cache 几乎无处不在,除了文件系统,存储有、RAID 卡有、磁盘可能也有,因此优化器还要考虑到这些缓存的存在
We also use a rough estimate “effective_cache_size” of the number of disk pages in Postgres + OS-level disk cache. (We can’t simply use NBuffers for this purpose because that would ignore the effects of the kernel’s disk cache.)
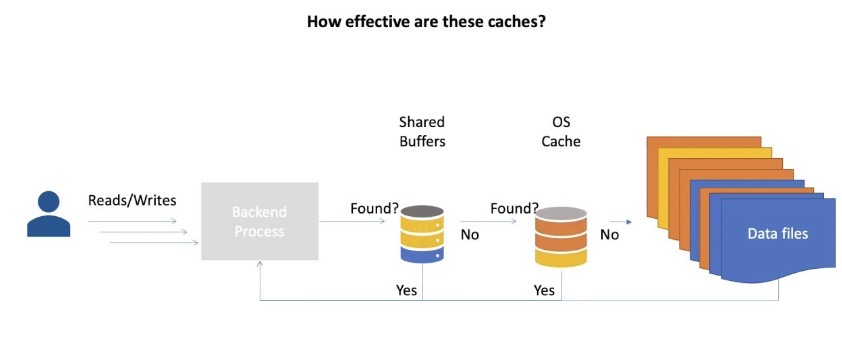
effective_cache_size 便是做这个的,简而言之,此参数用于告诉优化器有多少缓存可以用于查询,包括操作系统的缓存,按照一般经验,推荐设置为 RAM * 0.7
Sets the planner’s assumption about the effective size of the disk cache that is available to a single query.
然而官网的解释比较粗糙,其详细原理并没有过多阐述,只是给出了如何调整的建议,越高越可能使用索引,越低则倾向于使用顺序扫描。
This is factored into estimates of the cost of using an index; a higher value makes it more likely index scans will be used, a lower value makes it more likely sequential scans will be used
更高的数值会使得索引扫描更可能被使用,更低的数值会使得顺序扫描更可能被使用。
让我们看看代码中的注解,深入了解其原理。代码位于 costsize.c 中
1 | /* |
看起来很生硬,代码看得我云里雾里。简而言之,计算采用了 Mackert 和 Lohman 提出的模型,这个方法旨在估算有限 LRU 缓冲区下索引扫描的 I/O 成本。
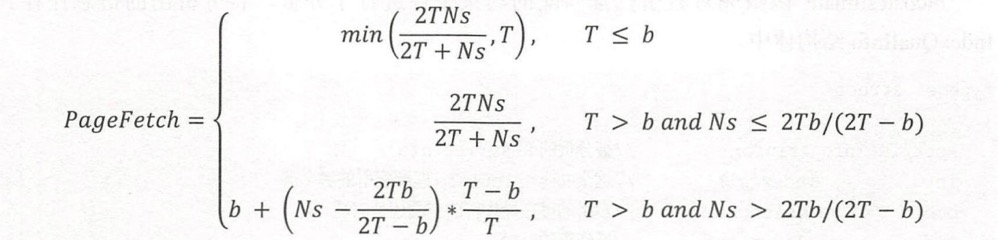
该公式基于以下参数:
T:表中的页面数N:表中的元组数s:约束条件的选择率b:表上的页面已经在缓存中的数量
index_pages_fetched 通过这个公式估算,在考虑到缓存效应后,实际需要获取的页面数量。这种方法帮助优化器在考虑不同查询执行计划时,更准确地估算 I/O 成本,从而选择最佳的查询执行策略。
假设当前查询中涉及的所有表的总页面是 total_pages,effective_cache_size 表示当前查询中涉及的所有表已经加载到缓存的总页面数,那么 (细节可以参照查询优化深度探索一书):

分析
代码过于晦涩,让我们看个实际例子:
1 | postgres=# CREATE TABLE t_ordered AS SELECT id, ceil(random() * 100000000) AS r FROM generate_series(1, 1000000) AS id; |
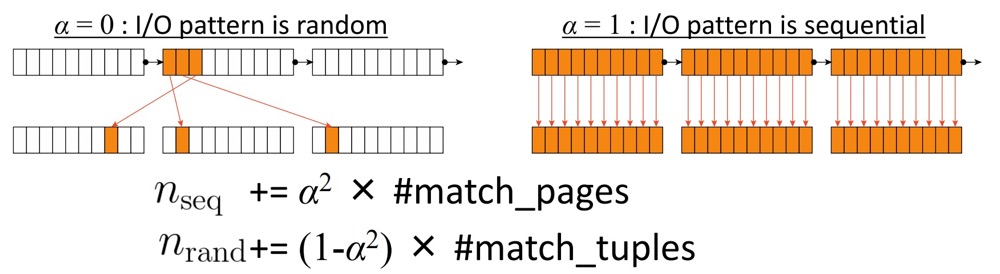
t_ordered 表的 id 列相关性为 1,表示完美关联,元组在磁盘上的物理顺序与索引中 TIDS 的逻辑顺序完美相关,那么每个页面只会被访问一次:Index Scan 节点将顺序地从一个页面跳到另一个页面,逐个读取元组。
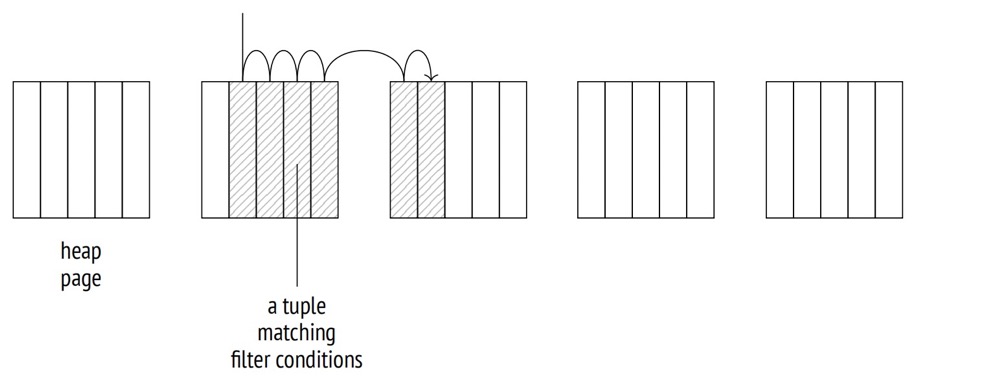
而 r 列为 0.0018,越接近 0 的值表示数据越杂乱无章,Index Scan 节点必须在页面之间跳转,而不是顺序读取;在最坏的情况下,访问的页面数量会达到获取的元组数量。
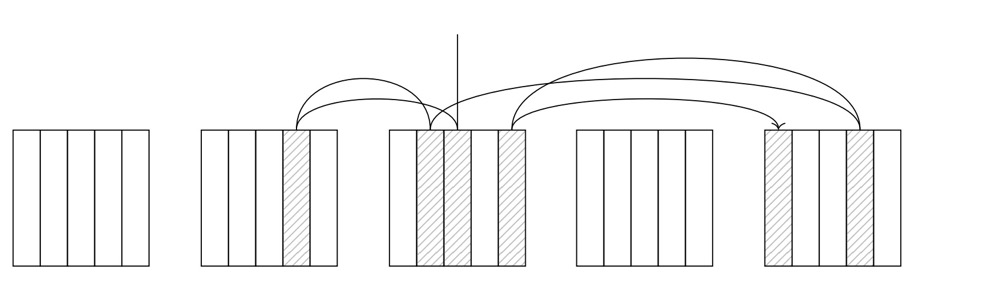
让我们粗略计算下总成本是如何计算出来的,记住前提是 id 列的相关性为 1
1 | postgres=# create index on t_ordered(id); |
优化器预估返回 98677 条,那么选择率为 0.098677
1 | postgres=# select 98677/reltuples as selectivity from pg_class where relname = 't_ordered'; |
索引扫描的成本包括:
- CPU cost of searching B+-tree,扫描 B 树的成本
- CPU cost of scanning index tuples in leaf pages,在叶子页搜索匹配元组的成本
- I/O cost of leaf pages,叶子页面的 I/O 成本
- I/O cost of heap pages,堆页面的 I/O 成本
- CPU cost of scanning heap tuples,扫描堆元组的成本
具体细节可以参考 https://www.interdb.jp/pg/pgsql03/02.html,此处粗略计算一下:
1 | postgres=# WITH costs(idx_cost, tbl_cost) AS ( |
我们计算出来的结果为 3348,和优化器算出来的 3351 接近,当然这是一个近似值。现在,让我们基于随机列的查询 (返回大致相同的行数,使选择率大致相同):
1 | postgres=# explain select * from t_ordered where r < 10000000; |
计算方式类似,不过此处是 random 列,相关性并非 1
1 | postgres=# WITH costs(idx_cost, tbl_cost) AS ( |
可以看到这种方式计算出来的值和优化器算出来的相差极大,原因不难理解,优化器考虑了缓存,默认的 effective_cache_size 为 4GB。
假如我们将其设为最小值,这样计算出来的值 394988.27 就和我们计算出来的值十分接近了。
1 | postgres=# set effective_cache_size to '8kB'; |
小结
小结一下
- effective_cache_size 用于告诉优化器有多少缓存可以用于查询,并非真正分配这么多,仅仅是一个参考值,当评估叶子页面的 I/O 成本时,优化器会考虑到 effective_cache_size,越大,索引扫描的成本就越低,也就越倾向于使用索引扫描
- 而 correlation 相关性决定了元组在磁盘上的物理顺序和逻辑顺序,也决定了堆页面的 I/O 成本,能否顺序访问的概率
参考
https://www.interdb.jp/pg/pgsql03/02.html
https://www.cybertec-postgresql.com/en/effective_cache_size-a-practical-example/
https://www.cybertec-postgresql.com/en/effective_cache_size-what-it-means-in-postgresql/