
前言
PostgreSQL16 正式发布已经有些时日了,之前也写过一篇新特性解读的文章 👉🏻PostgreSQL16新特性解读,其中提到了 pg_stat_io 这个视图,不过当时并没有花太多笔墨去描述,作为 16 里面为数不多且极具价值的特性,使得 PostgreSQL 的可观测性更上一层楼。当真是士别三日,当刮目相看呐。
前世今生
pg_stat_io,顾名思义——I/O 类的统计信息,在 16 以前,关于 I/O 类的统计视图比如 pg_stat_database.hits/reads、pg_statio_all_tables.hits/reads、pg_stat_bgwriter.backend_write 等,但是只能看个概况,且没有细分,I/O 又分为 flush(刷盘)、evict(页面置换)、extend(数据块扩展)、是否是bulk read/write、特殊情况比如表空间之间移动、临时文件等等,其次诸如 autovacuum、bgwriter 等常规进程,甚至后端进程也会在必要的时候主动去刷写脏块
- Writes = flushes + extends
- Reads and writes combined for all backend types
- I/O combined for all contexts and on all objects
- …
因此,I/O 类的可观测性对于我们分析数据库状态至关重要。可喜的是,在 16 版本中,Andres Freund 对 I/O 活动的可见性进行了重大改进 (没错,AIO 和 DIO 的主要核心大佬)。现在让我们深入其中,解析其中各项指标。
pg_stat_statements
首先需要提及的是 pg_stat_statements,抛砖引玉一下,其中也有相关可以观测 IO 时长的指标,但是前提是要将 **track_io_timing **参数打开。但是在某些平台下,这个参数打开会对性能有不小的影响,具体可以使用 pg_test_timing 进行测量,对于计时效率差的机器,也会影响 EXPLAIN ANALYZE 的输出精度
“Good results will show most (>90%) individual timing calls take less than one microsecond”
我这台机器的计时效率就没有问题。
1 | [postgres@xiongcc ~]$ pg_test_timing |
另外各位读者可能发现,pg_stat_statements 还分为了 shared、local 和 temp,云里雾里
1 | postgres=# \o | egrep "blk_write_time|blk_read_time" |
其实这三个指标分别对应了不同的对象
- Shared blocks contain data from regular tables and indexes,shared 对应常规的表和索引
- local blocks contain data from temporary tables and indexes,local 对应的是临时表及其索引
- while temp blocks contain short-term working data used in sorts, hashes, Materialize plan nodes, and similar cases,temp 对应的是排序、哈希等会用到的临时数据块
同理,pg_stat_io 中也有相关的 read_time / write_time / extend_time 等,也需要打开 track_io_timing。
数据块扩展
首先让我们验证一下数据块扩展——extend,对于extend,会受到一种特殊类型的锁保护 (也叫 extend),这种锁不会导致死锁,每次至多扩展 512 个页面,这个数字是动态变化的,随着阻塞进程数量动态变化,另外在索引清理的时候便会使用这种锁来禁止在索引扫描期间添加新的页面。
1 | postgres=# insert into t1 values(1); |
backend_type 等同于 pg_stat_activity.backend_type,比如 background worker
object:Relation or temp(orary) relation
context 分为多种:
- normal - reads and writes from/to shared buffers
- vacuum - I/O operations performed outside of shared buffers (vacuuming and analyzing)
- blkread - certain large read I/O operations done outside of shared buffers, e.g a large seq scan
- blkwrite - certain large write I/O operations done outside of shared buffers, such as COPY.
extends:Number of relation extend operations, each of the size specified in op_bytes (usually 8kB).,根据 block_size 决定
让我们多扩展点数据块
1 | postgres=# insert into t1 select * from generate_series(1,10000); |
有的细心读者可能发现这个大小相乘起来并不一样,其实不难理解,还包括有 FSM,当然如果还有 VM 的话。
1 | postgres=# select 48 * 8192 as size; |
那么这个指标有什么用呢?我们可以结合 extend_time 指标,获悉在扩展数据块期间,耗费了多久时间。
1 | postgres=# select backend_type,object,context,extends,op_bytes,extend_time from pg_stat_io where extends > 0; |
如果对于一个正在运行的实例,如果有大量的 extends,并且多于 writes,意味着你的 autovacuum / vacuum 可能需要调优了,或者存在大量的写入,vacuum 回收的空间不足以使新写入的数据复用旧空间。
数据块逐出
PostgreSQL 采用 clock-sweep 算法淘汰缓冲页,
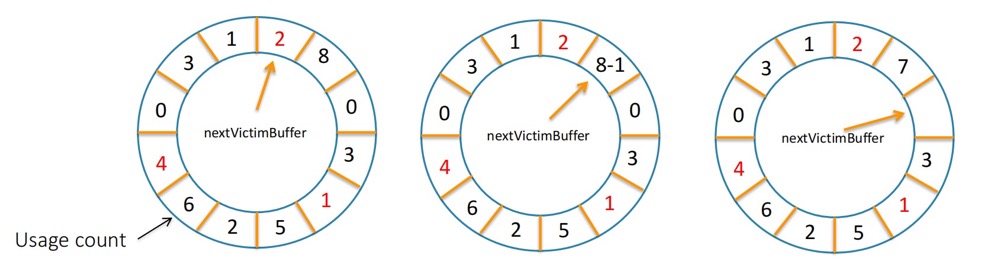
evictions 意味着要在 shared_buffers 选出一个受害者,逐出,给新欢腾出位置。那有的童鞋可能就会担心,如果我读入一个特别大的表,不就缓冲区给污染了?其实不然,PostgreSQL 还使用了一个名为 “ring buffer” 的环形缓冲区 (内核代码中还有 buffer ring),就是为了处理这种情况,具体细节可以参考 https://www.interdb.jp/pg/pgsql08/05.html

让我们验证一下,注意由于 pgbench_accounts 的大小大于 shared_buffers,因此常规的 select * from 是不行的,需要使用 pg_prewarm。
1 | postgres=# select backend_type,object,context,evictions from pg_stat_io where evictions > 0; |
可以看到,总共进行了 100946 次 evictions。
那么这个指标意味着什么呢?你的 shared_buffer 可能太小,其次大量逐出也就意味着更多的访问,更多的竞争,大量的 buffermapping 以及 io_in_progress_lock。
缓冲区命中
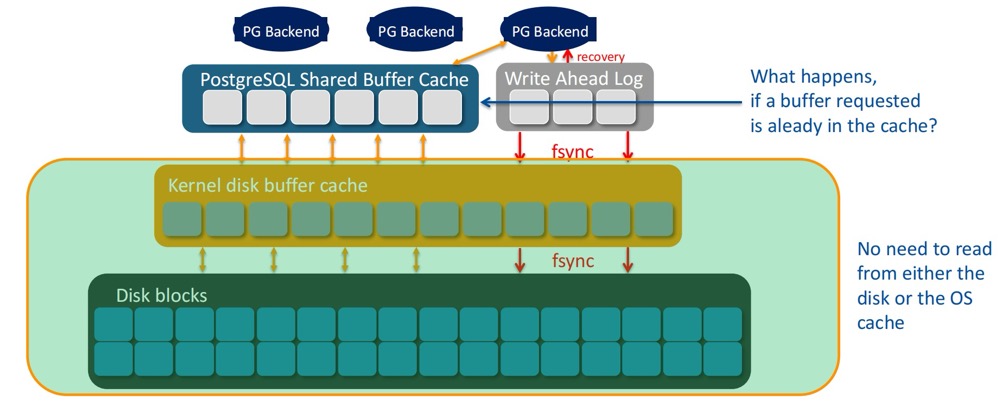
这个很好理解,无需访问 page cache 和 Disk 就获取到了需要的数据块。
1 | postgres=# select backend_type,object,context,hits from pg_stat_io where evictions > 0; |
此处我们关注 bulkwrite 和 bulkwrite,
- bulkread: Certain large read I/O operations done outside of shared buffers, for example, a sequential scan of a large table.
- bulkwrite: Certain large write I/O operations done outside of shared buffers, such as COPY.
这个指标十分直观,结合 evictions 综合分析,比如 hit 很高,evictions 很低,意味着你的 shared_buffers 对于此刻来说,至少足矣。不过需要注意的是,就算 hit miss,PostgreSQL 也可能从 buffer cache 中就找到了需要的数据块。
以往我们通过 pg_stat_database 来计算,现在有了 pg_stat_io,对于缓冲区命中率这个指标,计算就更为精确了:

Fsync
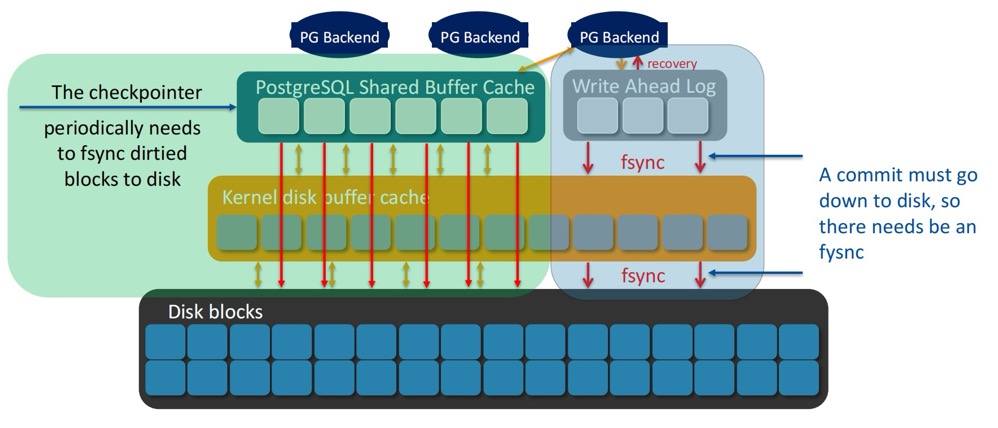
在事务提交时,我们知道 WAL record 是需要同步落盘的,而脏块是延迟写入的,由 checkpointer、bgwriter 亦或是 backend process,都会参与刷盘,最终的 fsync 由 checkpoint 发起。
因此理想状态下,backend process 应该永远不参与刷脏,我们可以结合 pg_stat_bgwriter 一起观察。
1 | postgres=# select context,fsyncs,fsync_time from pg_stat_io where fsyncs > 0; |
我这个例子就可以看到,normal (The default or standard context for a type of I/O operation. For example, by default, relation data is read into and written out from shared buffers. Thus, reads and writes of relation data to and from shared buffers are tracked in context normal.) 对应的 fsync_time 太高了,意味着你需要调整下 checkpoint 了。
小结
pg_stat_io 是 16 版本为数不多的惹眼特性,大大提升了 IO 类的可观测性如以往我们分析 pg_stat_bgwriter 发现 backend process 参与了大量刷脏,但是它没有考虑 autovacuum (pg_stat_bgwriter.buffers_backend 指标是包括了 vacuum 的,具有一定的误导性)
也没有告诉你真正的根因 (比如驱逐),现在我们就可以结合 pg_stat_io.writes 指标,分析背后的种种。其次 ring buffer 的观察,在以前的版本中也是一个黑盒,看不到任何有关指标,现在就可以观察 bulk_read 和 bulk_write,来分析是否发生了大批量的读取和写入。
目前社区也在讨论进一步提升 pg_stat_io:
- Tracking of system-wide buffer cache hits (to allow calculating an accurate buffer cache hit ratio)
- Cumulative system-wide I/O times (not just I/O counts as currently present in
pg_stat_io) - Better cumulative WAL statistics (i.e. going beyond what pg_stat_wal offers)
- Additional I/O tracking for tables and indexes
- “bypass” IO
- consolidated WAL stats
参考
https://pganalyze.com/blog/pg-stat-io
https://www.interdb.jp/pg/pgsql08/05.html
Increased I/O Observability with pg_stat_io
Getting the most out of pg_stat_io