
前言
上周五帮同事看了一个内存泄漏 mem leak 的问题,简而言之,就是使用 pmap -d 发现 writeable/private 的内存持续上涨。
赶巧,今晚又有一位朋友私信我,怀疑也是某数据库内存泄露了:
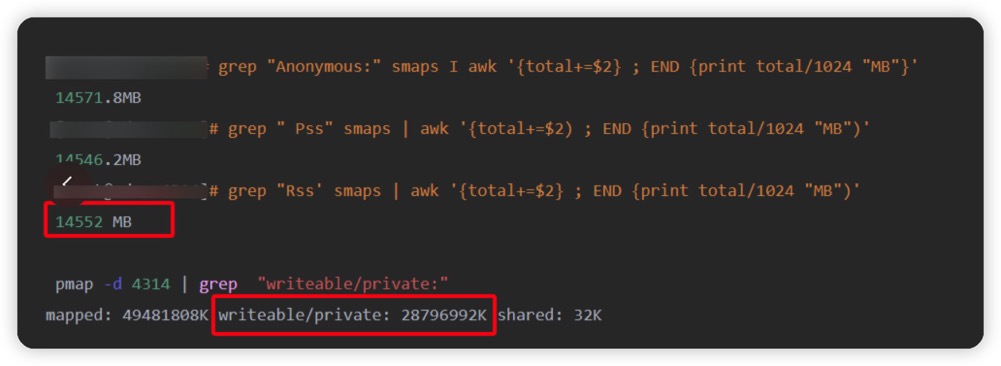
借此机会,我也看了一下 pmap -d 的内核代码,简单聊聊。
内存分析工具
内存的分类很多,可以细分为
- 私有内存,Private Memory
- 共享内存,Shared Memory
- 匿名内存,Anonymous Memory
- File-Backend,有文件背景的页面,比如代码段、比如 read/write 读写的文件、有对应的硬盘文件,因此如果要交换,可以直接和硬盘对应的文件进行交换
- Swap,匿名页,如 stack,heap,CoW 后的数据段等;他们没有对应的硬盘文件,因此如果要交换,只能交换到 swap 分区
至于私有和共享又可以进一步划分:
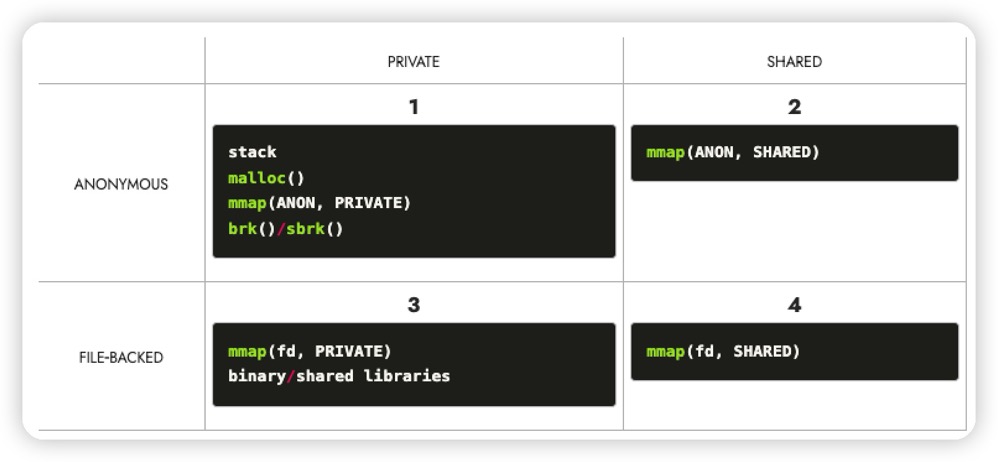
- 私有匿名映射 - 通常用于内存分配,glibc 库里提供的用于动态申请堆内存的 malloc 函数就是对系统调用 sbrk 和 mmap 的封装。
- 共享匿名映射 - 通常用于进程间共享内存,PostgreSQL 里面我们熟悉的 /dev/zero,父子进程间通信
- 私有文件映射 - 通常用于加载动态库
- 共享文件映射 - 通常用于内存映射IO,进程间通信
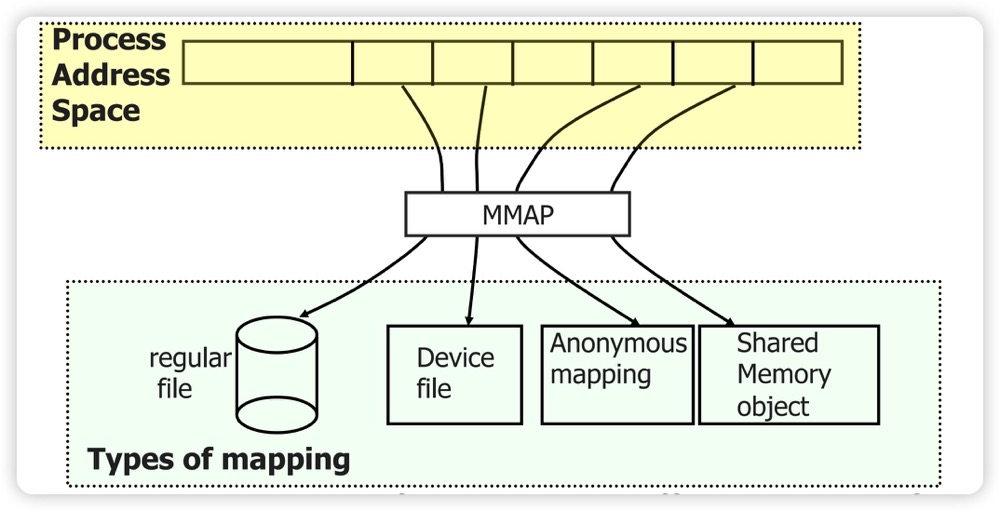
因此我们在分析内存的时候,要分清楚到底是共享内存还是私有内存,是不是匿名页,也要搞清 PSS/USS/RSS/VSS 这类指标的差异:
- VSS (reported as VSZ from ps) is the total accessible address space of a process. This size also includes memory that may not be resident in RAM like mallocs that have been allocated but not written to or mmap()ed files on disk, etc
- RSS is the total memory actually held in RAM for a process. RSS can be misleading, because it reports the total all of the shared libraries that the process uses, even though a shared library is only loaded into memory once regardless of how many processes use it. It also counts all other shared pages, such as the copy-onwrite pages still shared with the parent after fork(), an important usecase for current LHC multicore usage.
- PSS differs from RSS in that it reports the proportional size of its shared pages
- USS is the total private memory for a proces, i.e. that memory that is completely unique to that process.
我经常使用的是 TOP(RSS,因此 TOP 分析内存是不准的)、pmap、smem、pidstat、sar 等,都可以用于分析内存。此文让我们聚焦于 pmap。
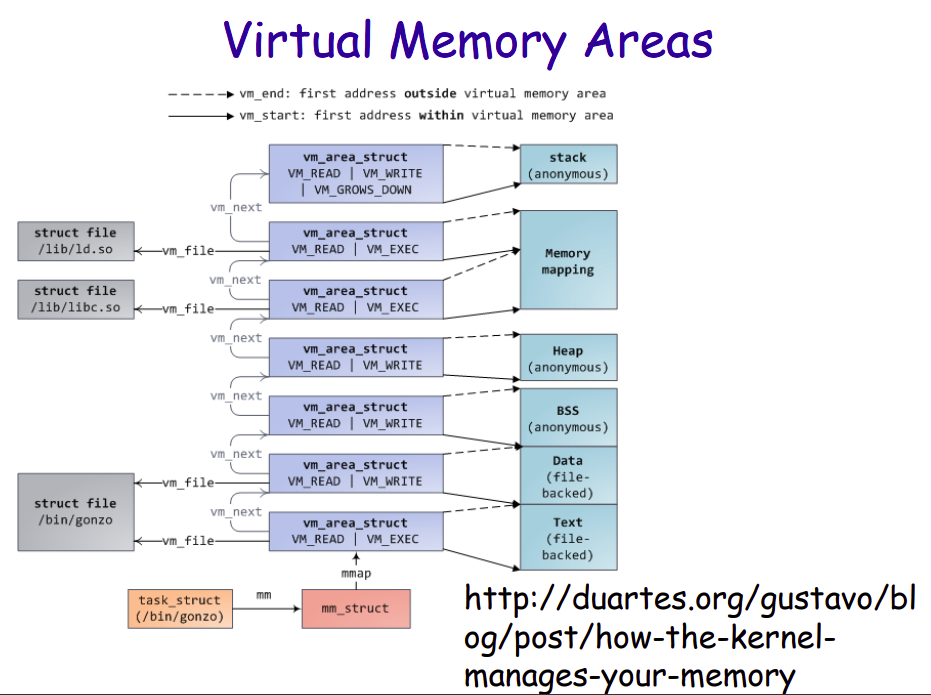
vm_area_struct
pmap 用于显示进程的内存映像,显式每个 vm_area_struct 指向的虚拟内存区域,所指向的虚拟内存区域又可以细分为代码段、数据段、堆、内存映射区、栈等等 (这块不熟悉的自行谷歌)。
1 | struct vm_area_struct { |

- heap堆
堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc()等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free()等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)。
- stack栈
是用户存放程序临时创建的局部变量,也就是说我们函数括弧{}中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进后出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把栈看成一个寄存、交换临时数据的内存区。
- bss段
BSS段属于静态内存分配。通常是指用来存放程序中未初始化的全局变量和未初始化的局部静态变量。未初始化的全局变量和未初始化的局部静态变量默认值是0,本来这些变量也可以放到data段的,但是因为它们都是0,所以它们在data段分配空间并且存放数据0是没有必要的。在程序运行时,才会给BSS段里面的变量分配内存空间。在目标文件(*.o)和可执行文件中,BSS段只是为未初始化的全局变量和未初始化的局部静态变量预留位置而已,它并没有内容,所以它不占据空间。section table中保存了BSS段(未初始化的全局变量和未初始化的局部静态变量)内存空间大小总和。可以通过objdump -h *.o命令查看到。
- data段
数据段(data segment)通常是指用来存放程序中已初始化的全局变量和已初始化的静态变量的一块内存区域。数据段属于静态内存分配。
- text段
代码段(code segment / text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读,某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
**每一个VMA都有如下的一系列数据,**我们可以通过 /proc/xxx/smaps 进行查看。
1 | 08048000-080bc000 r-xp 00000000 03:02 13130 /bin/bash |
此处我们重点看下 vm_flags,用于标记这块虚拟内存区域的行为规范,此处我们只关注如下几个
- VM_READ:可读
- VM_WRITE:可写
- VM_EXEC:可执行
- VM_SHARD:进程间共享
比如代码段这块内存区域的权限是可读,可执行,但是不可写。数据段具有可读可写的权限但是不可执行。堆则具有可读可写,可执行的权限。栈一般是可读可写的权限,一般很少有可执行权限。而文件映射与匿名映射区存放了共享链接库,所以也需要可执行的权限。
因此回到 pmap,这个命令背后的实现原理就是通过遍历内核中的这个 vm_area_struct 获取的。那让我们再详细剖析下 pmap -d 的内核实现原理是怎样的:
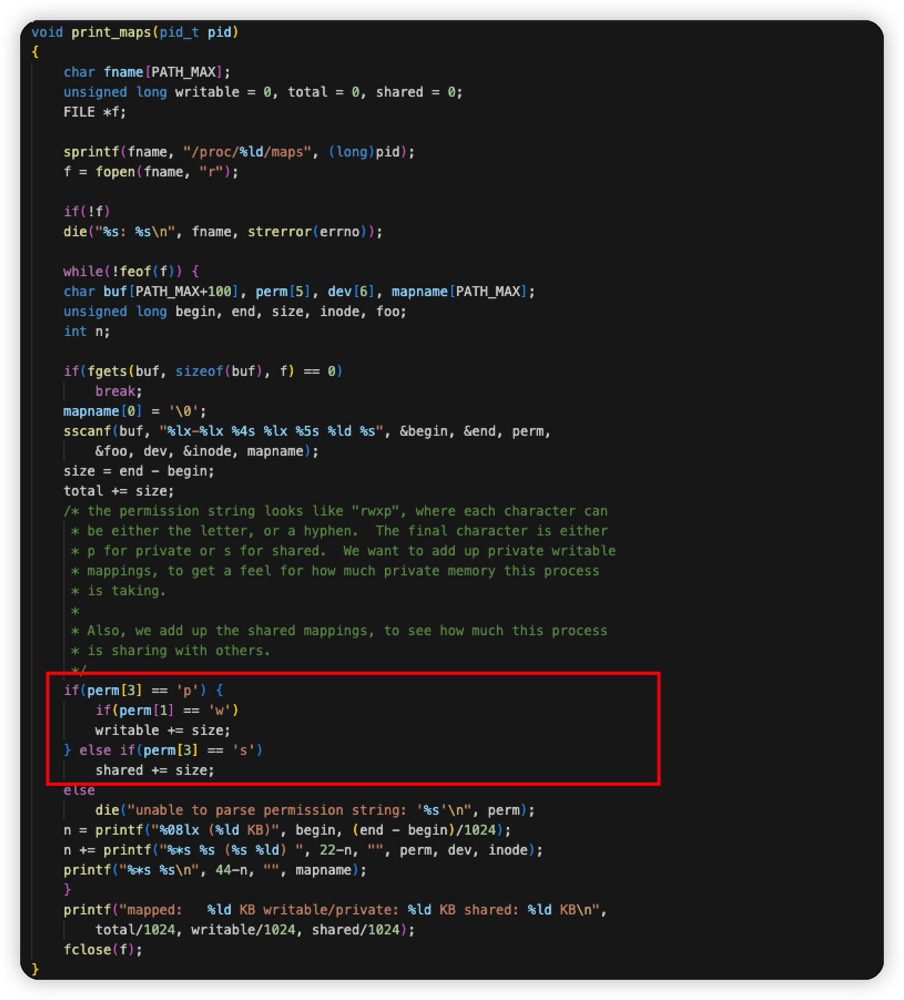
可以看到,pmap 就是读取的 /proc/进程号/maps 文件进行计算的,并且 writable/private 的逻辑也很简单
- 是否是私有的 private
- 是否是可写的 writable
- 全部加起来,就是我们看到的 pmap -d 的 writable/private 指标
那让我们模拟一下,一段简短的内存泄露代码,没有及时 FREE。
1 |
|
运行起来,然后观察其内存使用状况,不一会儿就在缓慢上涨了
1 | [postgres@xiongcc ~]$ while true; do pmap -d 27647 | tail -1; sleep 2; done |
同时让我们检查一下 smaps
1 | [postgres@xiongcc ~]$ cat /proc/27647/smaps | egrep -w 'Size:' |
可以看到,pmap -d 本质上就是将 smaps 文件的 VMA 取了出来,那让我们手动计算一下,看看是不是 848 KB。
1 | [postgres@xiongcc ~]$ cat /proc/27647/smaps | awk '/^[0-9a-f]+-[0-9a-f]+/ {address=$1; permissions=$2; path=$NF; getline; size=$2; print "Address: " address ", Permissions: " permissions ", Size: " size ", Path: " path}' |
按照前面的逻辑,p → w → 相加,那么就是 4 + 660 + 8 + 20 + 12 + 4 + 4 + 4 + 132 = 848 KB,可以看到,对得上了。
注意此处的 Path:0 因为是 shell 的原因,以 08048000-080bc000 r-xp 00000000 03:02 13130 /bin/bash 为例,分别表示
- 虚拟内存段的开始和结束位置
- 内存段的权限,分别是可读、可写、可运行、私有或共享,最后一位p代表私有,s代表共享
- 该虚拟内存段起始地址在对应的映射文件中以页为单位的偏移量,对匿名映射,它等于0或者vm_start/PAGE_SIZE
- 文件的主设备号和次设备号。对匿名映射来说,因为没有文件在磁盘上,所以没有设备号,始终为00:00。对有名映射来说,是映射的文件所在设备的设备号。
- 被映射到虚拟内存的文件的索引节点号,通过该节点可以找到对应的文件,对匿名映射来说,因为没有文件在磁盘上,所以没有节点号,始终为00:00。
- 被映射到虚拟内存的文件名称。后面带(deleted)的是内存数据,可以被销毁。对有名来说,是映射的文件名。对匿名映射来说,是此段虚拟内存在进程中的角色。[stack]表示在进程中作为栈使用,[heap]表示堆。其余情况则无显示。
如果是无显示的情况下,我问了一下 GPT

以我这段简短的 C 代码为例,其计算原理也就明白了:将私有的(排除了共享库),可写的(排除只读代码段、包括数据段、栈、堆)相加,得到私有内存。和代码中的原理相同。
1 | /* the permission string looks like "rwxp", where each character can |
此例中内存大头便是堆 heap,因为我一直在源源不断地申请内存;其次也将 /usr/lib64/libc-2.17.so 计算了进去。
小结
以上便是 pmap -d 的实现原理,通过这个例子,想必各位对于 Linux 复杂的内存机制会有更多的思考。另外,smem 工具也是一款推荐查看内存的工具,这二者的统计方式也存在较大差异,下面是 USS/PSS/RSS,可以看到 smem 是将 USS 缓慢累计的,计算方式必然有所不同。
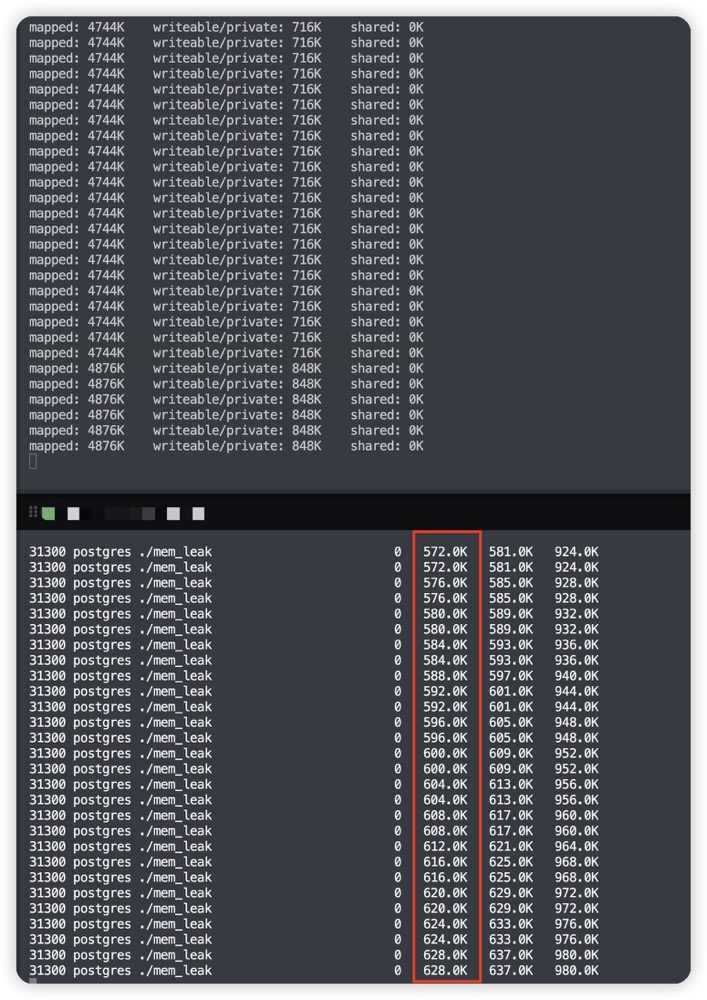
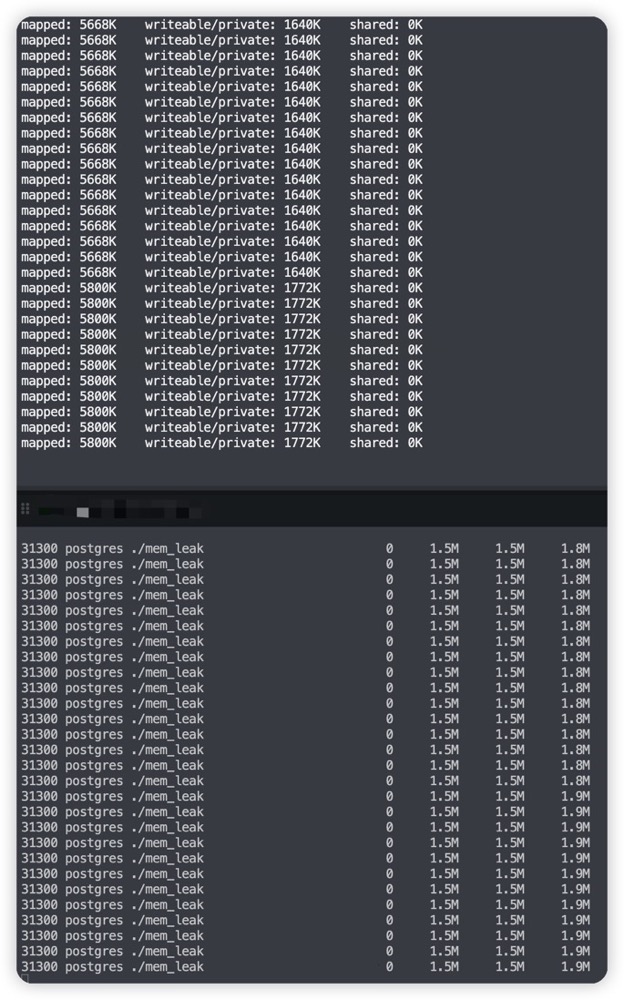
后面找时间再分析一下 smem 的实现原理。That’s all!
参考
https://techtalk.intersec.com/2013/07/memory-part-2-understanding-process-memory/