前言 第三篇VACUUM内核原理解析姗姗来迟,前两篇介绍了 index by pass、skip_pages 等
深入浅出VACUUM内核原理(上) 深入浅出VACUUM内核原理(中): index by pass
今天与各位再次聊聊 vacuum 其他鲜为人知的特性和有趣的特性——碎片整理。
vacuum phase 让我们先回顾下 vacuum 各个阶段会做的事情。在代码中总共细分了 6 个阶段,对应 pg_stat_progress_vacuum 中的各个阶段,此处我们简化一下,划分为 3 个阶段。
1 2 3 4 5 6 7 #define PROGRESS_VACUUM_PHASE_SCAN_HEAP 1 scanning heap #define PROGRESS_VACUUM_PHASE_VACUUM_INDEX 2 vacuuming indexes #define PROGRESS_VACUUM_PHASE_VACUUM_HEAP 3 vacuuming heap #define PROGRESS_VACUUM_PHASE_INDEX_CLEANUP 4 cleaning up indexes #define PROGRESS_VACUUM_PHASE_TRUNCATE 5 truncating heap #define PROGRESS_VACUUM_PHASE_FINAL_CLEANUP 6 performing final cleanup
当然,也可以参照 The Internals of PostgreSQL 中讲述的流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 (1 ) FOR each table (2 ) Acquire a ShareUpdateExclusiveLock lock for the target table (3 ) Scan all pages to get all dead tuples, and freeze old tuples if necessary (4 ) Remove the index tuples that point to the respective dead tuples if exists (5 ) FOR each page of the table (6 ) Remove the dead tuples, and Reallocate the live tuples in the page (7 ) Update FSM and VM END FOR (8 ) Clean up indexes (9 ) Truncate the last page if possible (10 Update both the statistics and system catalogs of the target table Release the ShareUpdateExclusiveLock lock END FOR (11 ) Update statistics and system catalogs (12 ) Remove both unnecessary files and pages of the clog if possible
first phase 第一阶段对应 scanning heap 和 vacuuming indexes :
扫描表,获取死元组的列表,此过程受到 maintenance_work_mem 参数的影响
根据需要,冻结相应元组
清理索引项 (指向死元组的条目)
第一阶段有一个细节需要提一下:vacuum 和 autovacuum 用于存放死元组的内存有上限——1GB,意味着即使你将 maintenance_work_mem 或 autovacuum_work_mem 参数设置为最大值 (最大值超过了 1GB) 也没用。这和默认的 segment size limit 相匹配。
此限制在官网上也有所描述:
maintenance_work_mem:Note that for the collection of dead tuple identifiers, VACUUM is only able to utilize up to a maximum of 1GB of memory.
autovacuum_work_mem:For the collection of dead tuple identifiers, autovacuum is only able to utilize up to a maximum of 1GB of memory, so setting autovacuum_work_mem to a value higher than that has no effect on the number of dead tuples that autovacuum can collect while scanning a table.
second phase
移除堆中死元组 (移除表中死元组是在这个阶段做的,第一阶段收集索引条目,然后在此阶段删除对应死元组)
更新 FSM 和 VM 文件 (per page)
整理碎片 (per page)
此阶段主要会涉及到一个碎片整理,本文也会重点聊一聊。
final phase
调用 index_vacuum_cleanup 执行 index cleanup (以前的函数叫 lazy_cleanup_index)
更新系统表和相关统计信息,比如 relages/reltuples/relallvisible 等等
堆截断,满足阈值则”咬断”文件末尾的尾巴
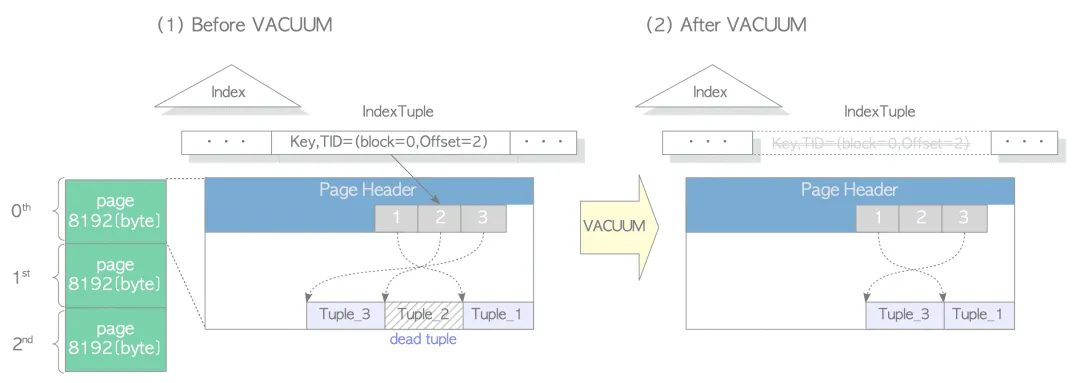
当一个索引页面中的所有元组都被删除,即索引页面被删空后,vacuum 会将这个页面从BTREE 中删除,(index cleanup本想直译成索引清理,但是和index vacuuming就有点重复的味道了,所以保留原样),删除操作会从叶子节点开始,14 中做了一个优化,我印象深刻: Reduced Bloat with Bottom-Up Deletion。
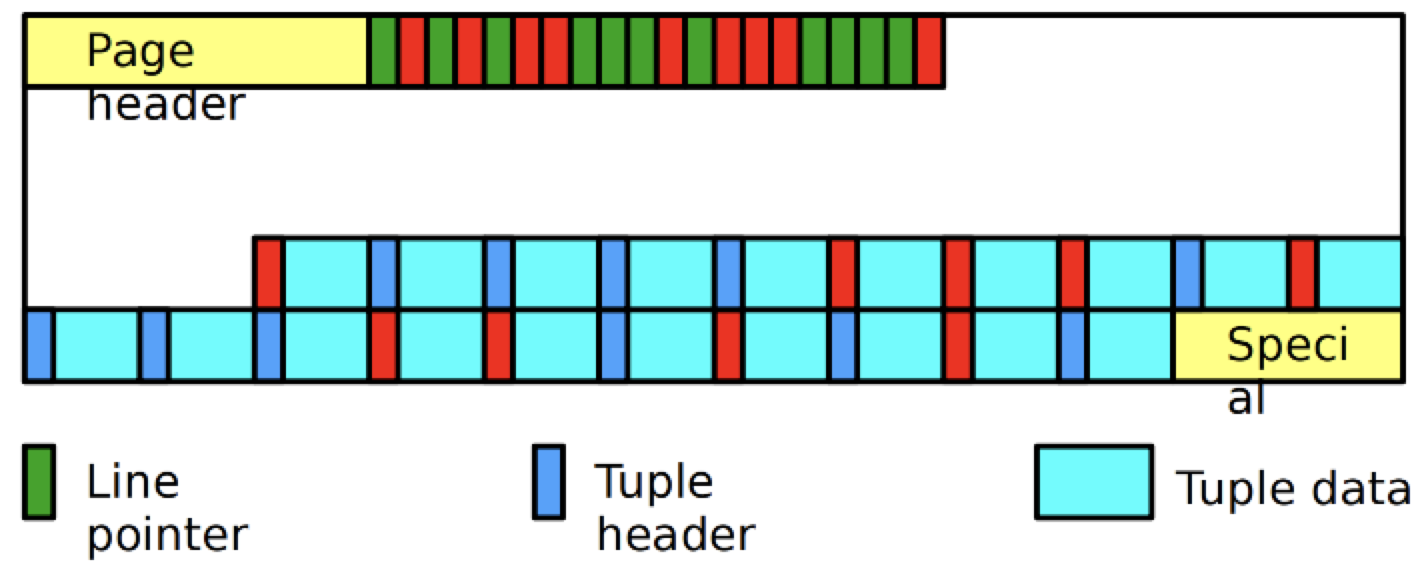
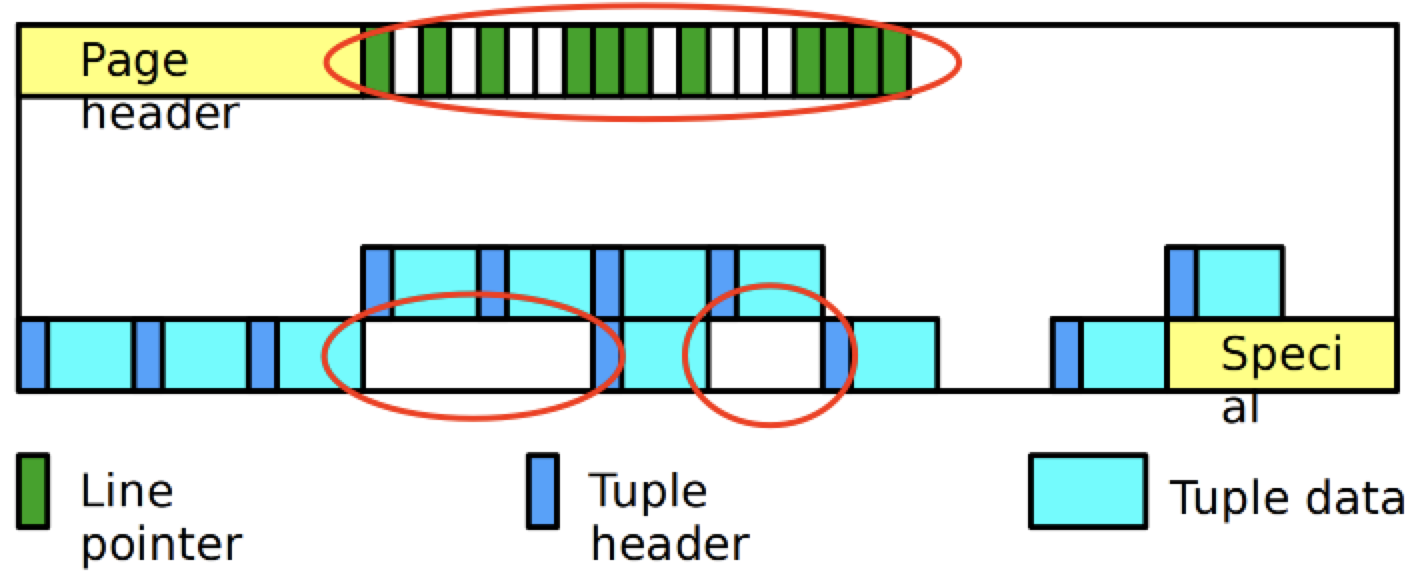
碎片整理 这一篇让我们重点聊聊碎片整理。我们知道 vacuum 用于清理页面内的死元组
那么清理完之后,页面内就会有”空洞”,页面内的碎片
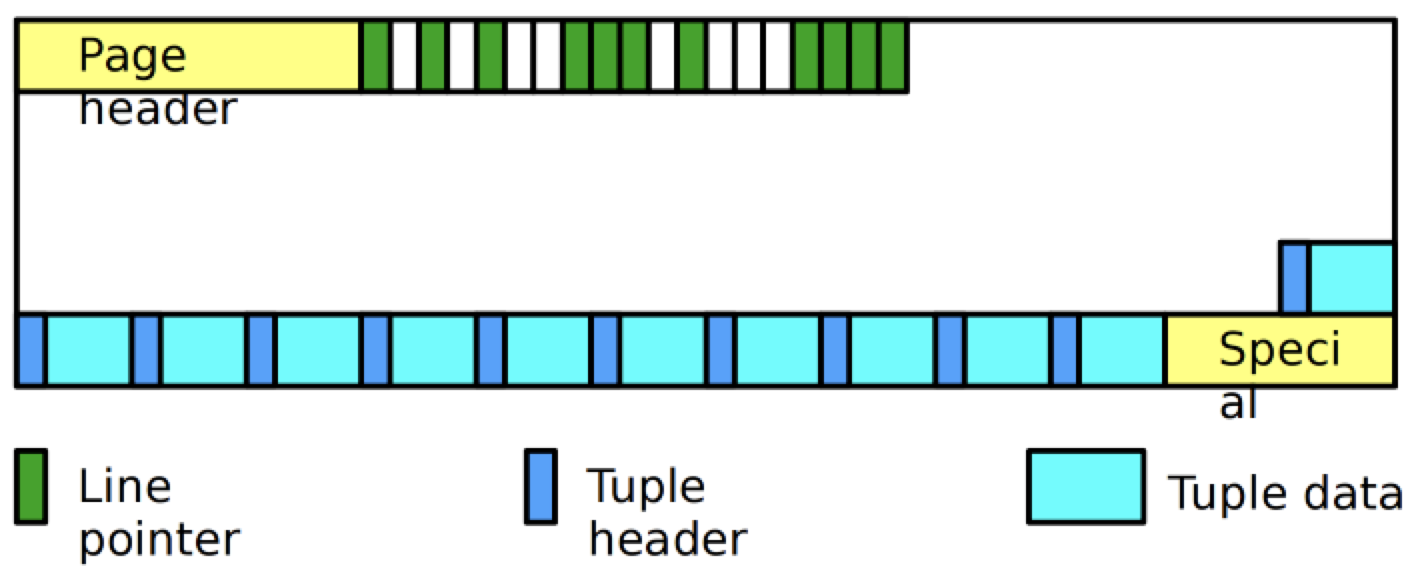
为此,PostgreSQL 会重排,将数据重新挪动,紧实碎片
不过此阶段那些 line pointer 并不会被移除,在后面重用,如果 LP 被移除的话,那么相应的索引也需要改变。
可以看到,Tuple_3 的位置到了被删除的 Tuple_2 的位置。
这便是碎片整理,可以防止页面内碎片化。让我们验证一下
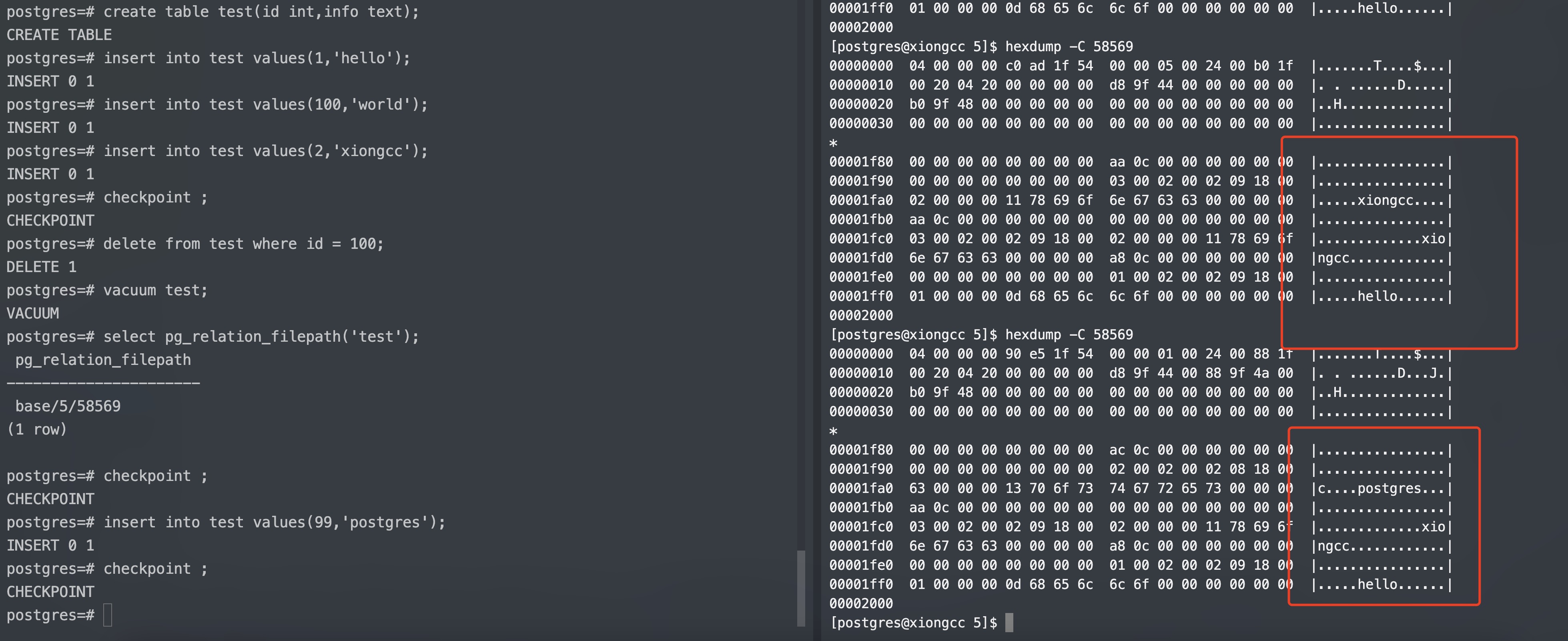
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 postgres= # create table test(id int ,info text); CREATE TABLE postgres= # insert into test values (1 ,'hello' ); INSERT 0 1 postgres= # insert into test values (100 ,'world' ); INSERT 0 1 postgres= # insert into test values (2 ,'xiongcc' ); INSERT 0 1 postgres= # checkpoint ; CHECKPOINT postgres= # select pg_relation_filepath('test' ); pg_relation_filepath base/ 5 / 58559 (1 row ) postgres= # SELECT lp,lp_off,lp_flags,t_ctid,t_data,infomask(t_infomask,1 )as infomask,infomask(t_infomask,2 )as infomask2 FROM heap_page_items(get_raw_page('test' , 0 )); lp | lp_off | lp_flags | t_ctid | t_data | infomask | infomask2 1 | 8152 | 1 | (0 ,1 ) | \x010000000d68656c6c6f | XMAX_INVALID| HASVARWIDTH | 2 | 8112 | 1 | (0 ,2 ) | \x640000000d776f726c64 | XMAX_INVALID| HASVARWIDTH | 3 | 8072 | 1 | (0 ,3 ) | \x020000001178696f6e676363 | XMAX_INVALID| HASVARWIDTH | (3 rows ) postgres= # \! sh encode.sh TID: 1 data offset : 8152 length: 34 binary : 0000000001000100 1001111111011000 TID: 2 data offset : 8112 length: 34 binary : 0000000001000100 1001111110110000 TID: 3 data offset : 8072 length: 36 binary : 0000000001001000 1001111110001000 TID: 4 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 5 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 6 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 7 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 8 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 9 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 10 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000
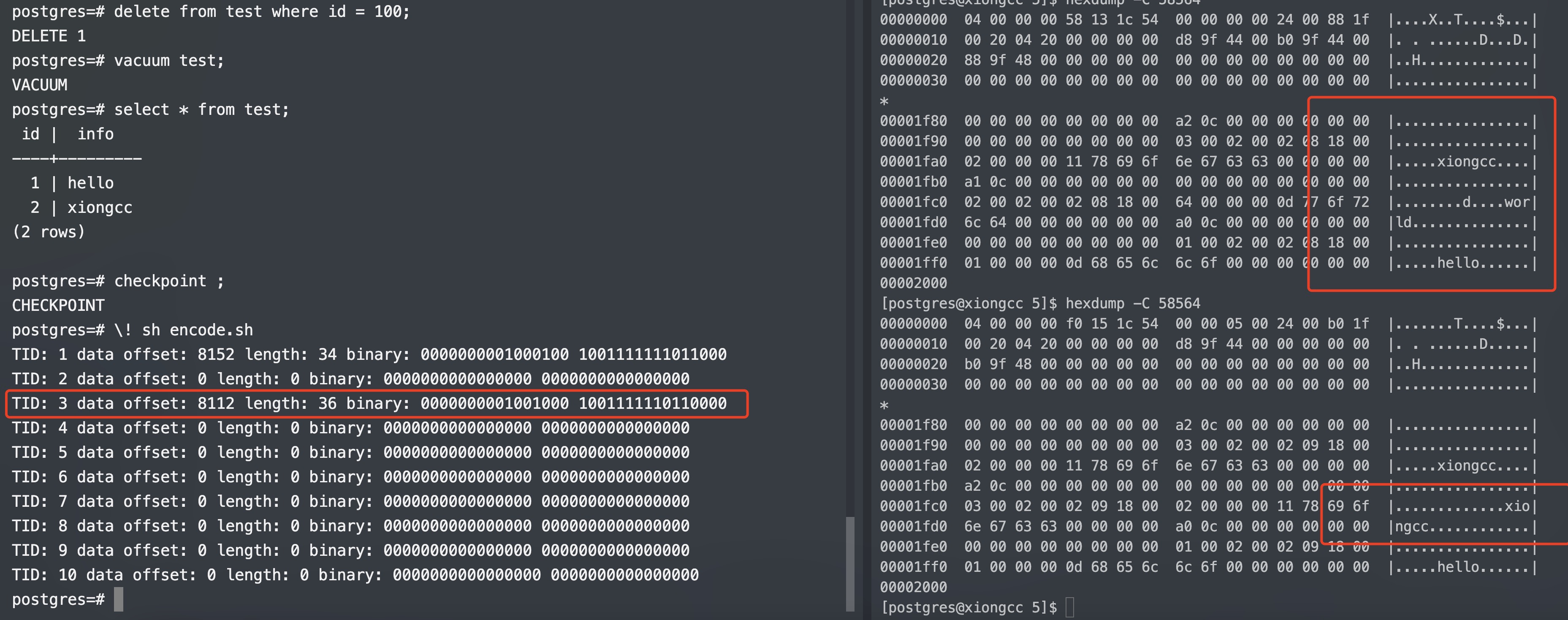
现在让我们删除第二条数据,同时做个 vacuum,观察底层数据文件的变化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 postgres= # delete from test where id = 100 ; DELETE 1 postgres= # vacuum test; VACUUM postgres= # checkpoint; CHECKPOINT postgres= # SELECT lp,lp_off,lp_flags,t_ctid,t_data,infomask(t_infomask,1 )as infomask,infomask(t_infomask,2 )as infomask2 FROM heap_page_items(get_raw_page('test' , 0 )); lp | lp_off | lp_flags | t_ctid | t_data | infomask | infomask2 1 | 8152 | 1 | (0 ,1 ) | \x010000000d68656c6c6f | XMAX_INVALID| XMIN_COMMITTED| HASVARWIDTH | 2 | 0 | 0 | | | | 3 | 8112 | 1 | (0 ,3 ) | \x020000001178696f6e676363 | XMAX_INVALID| XMIN_COMMITTED| HASVARWIDTH | (3 rows ) postgres= # \! sh encode.sh TID: 1 data offset : 8152 length: 34 binary : 0000000001000100 1001111111011000 TID: 2 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 3 data offset : 8112 length: 36 binary : 0000000001001000 1001111110110000 TID: 4 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 5 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 6 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 7 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 8 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 9 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 10 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000
注意观察第三行数据的偏移量,已经从 8072 被挪到了 8112,并且第二行数据的 lp_flags 变成了 0,说明行指针并没有变动。
0 : LP_UNUSED , 未使用,对应的 lp_len 总是为 0
1 : LP_NORMAL , 正常使用,对应的 lp_len 总是大于 0
2 : LP_REDIRECT , HOT 特性中重定向的 Tuple,对应的 lp_len = 0
3 : LP_DEAD , dead 状态,对应的存储空间 lp_len 不确定,可能为 0,可能大于 0
现在,让我们重新插入第二行数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 postgres= # insert into test values (100 ,'world' ); INSERT 0 1 postgres= # checkpoint; CHECKPOINT postgres= # \! sh encode.sh TID: 1 data offset : 8152 length: 34 binary : 0000000001000100 1001111111011000 TID: 2 data offset : 8072 length: 34 binary : 0000000001000100 1001111110001000 TID: 3 data offset : 8112 length: 36 binary : 0000000001001000 1001111110110000 TID: 4 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 5 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 6 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 7 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 8 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 9 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 TID: 10 data offset : 0 length: 0 binary : 0000000000000000 0000000000000000 postgres= # SELECT lp,lp_off,lp_flags,t_ctid,t_data,infomask(t_infomask,1 )as infomask,infomask(t_infomask,2 )as infomask2 FROM heap_page_items(get_raw_page('test' , 0 )); lp | lp_off | lp_flags | t_ctid | t_data | infomask | infomask2 1 | 8152 | 1 | (0 ,1 ) | \x010000000d68656c6c6f | XMAX_INVALID| XMIN_COMMITTED| HASVARWIDTH | 2 | 8072 | 1 | (0 ,2 ) | \x640000000d776f726c64 | XMAX_INVALID| HASVARWIDTH | 3 | 8112 | 1 | (0 ,3 ) | \x020000001178696f6e676363 | XMAX_INVALID| XMIN_COMMITTED| HASVARWIDTH | (3 rows ) postgres= # select * from test; id | info 1 | hello 100 | world 2 | xiongcc (3 rows )
可以看到,第二行数据给人还在删除前”位置”的错觉,但是可以看到其偏移量已经变成了 8072,说明位于底层数据文件的第三行了。这是因为查询是顺序扫描的,根据 LP 挨个取出相应的数据,所以是 (0,1),(0,2),(0,3),这便是碎片整理。
深入细节 让我们再深入一下,页内碎片整理是如何实现的:
删除第三行数据然后拷贝到第二行的位置?
这样会不会导致膨胀?
其实我刚刚的操作已经透露了答案,第二次解析数据块,第三行数据还在那里。让我们用 hexdump 再来验证一下
十分清晰,将第三行数据”拷贝”到了第二行的位置。让我们看下源码实现,我通过 DTRACE 很快就定位到了源码的位置:compactify_tuples
可以看到其实现就是通过 memcpy 和 memmove 来进行拷贝的,包括 HOT 更新也是类似流程 PageRepairFragmentation → compactify_tuples。
因此这个现象就说得通了,当 vacuum 的时候,调用 compactify_tuples 进行元组拷贝,使页面紧实,随着后续的插入直接覆盖挪动留下来的”坑”
当 PostgreSQL 异常宕机的时候,也会使用 compactify_tuples 进行恢复,备库回放也会。
The compactify_tuples function is used internally in PostgreSQL:
when PostgreSQL starts up after a non-clean shutdown—called crash recovery
by the recovery process that is used by physical standby servers to replay changes (as described in the write-ahead log) as they arrive from the primary server
by VACUUM
更多细节可以参考 https://www.postgresql.org/message-id/CA+hUKGKMQFVpjr106gRhwk6R-nXv0qOcTreZuQzxgpHESAL6dw@mail.gmail.com 此邮件讨论,简而言之,14 版本后 VACUUM 执行 compactify_tuples 的速度快了 25% 左右。
小结 页面内移动元组,可以避免页面内碎片,好处就是提升空间利用率,减少空洞。
不知不觉已经写了 3 篇 VACUUM 内核剖析了,后续有空再写深入浅出VACUUM内核原理最终章——TOAST和物化视图的处理内幕。让我们拭目以待。
另外,深入剖析PostgreSQL统计信息素材也已完工,后续会考虑公开。
参考 https://techcommunity.microsoft.com/t5/azure-database-for-postgresql/speeding-up-recovery-and-vacuum-in-postgres-14/ba-p/2234071
https://blog.csdn.net/obvious__/article/details/126415393
https://developer.aliyun.com/article/647442
https://cloud.tencent.com/developer/article/2185527
https://www.postgresql.org/message-id/CA+hUKGKMQFVpjr106gRhwk6R-nXv0qOcTreZuQzxgpHESAL6dw@mail.gmail.com