
前言
Greenplum,在MPP领域常青不凋,又同为PostgreSQL系,加之Greenplum 7前些天也发布了,于是近些天我将由陈淼编著的《Greenplum-Database管理员指南6.2.1》这本PDF看完了,这本著作包含作者十多年的经验与心得,阅读完之后收获很大,在此也简单聊聊个人的心得与见解。
常青树
Greenplum从物理层面来看,整个集群内含有多个PostgreSQL实例,大号的PostgreSQL,节点之间的信息交互通过高速互联网络实现,通过将数据分布到多个节点上来实现规模数据的存储,再通过多个计算节点协同计算处理来提高查询性能。
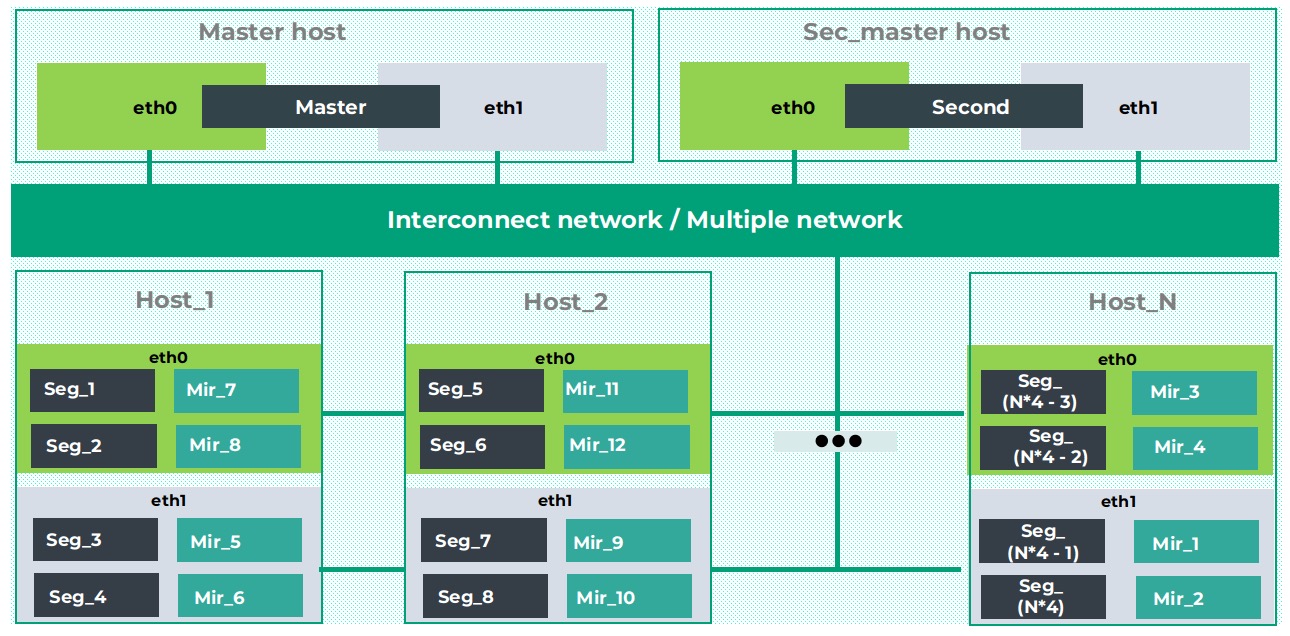
整体架构如下:
- master节点主要存储元数据,负责执行计划的生成与查询接入
- segment节点即计算节点,负责存储实际数据的存储以及分布式执行计划的执行
- interconnect network,高速内联网络,主要用于集群间的通信与数据重分布
Greenplum主要还是用于AP领域,虽然最新版已经基于12的内核,但是相较于Citus、PGXC系接入层可横向扩展的架构,master目前还无法横向扩展,即单master节点,TP能力上限取决于单master的瓶颈,所以不妨称为”大AP小TP”,毕竟我始终认为HTAP是有侧重点的,要么AP强TP弱点,要么TP拿手AP弱势。
分布键
由于数据是分散存储在多个计算节点中,因此不难理解,查询会涉及到多个计算节点的协同,那么如何预防”木桶效应”、”短板效应”是能否用好Greenplum的关键因素之一,即数据分布情况,假如分布键 (分布键决定了数据如何分布) 的选择不理想,比如数据分布不均,那么按照HASH策略分布的话,数据便会集中存储在某几个计算节点中,这样就会造成”一人有难,他人围观”的尴尬局面,其中一个节点忙的热火朝天,其他节点无所事事。

其次就是多表关联,也与分布键息息相关,假如参与关联的表的分布键相同 (当然数据类型也要一致),那么可以在计算节点本地就完成关联操作,因为不同分布键,数据分布策略也不同,那么就需要涉及到数据的移动 (在Greenplum中叫做Motion算子),不难想象,要移动的数据量越多,对于interconnect也是个很大的挑战,因此GPADMIN书中也提及:
必须使用万兆网络作为内部互联网络,否则,一定会遭受很多网络方面的困扰。
这个机制也适用于其他需要设计分布键的数据库。
当然Greenplum也可能会选择将数据进行”广播”,有类似的代价参数:gp_motion_cost_startup、gp_motion_cost_per_row以决定是广播还是重分布。如果单个字段不能实现数据均匀分布,则考虑使⽤两个字段做分布键 (当然前提是关联条件最好都包括这两个字段)。作为分布键的字段最好不要超过两个。Greenplum使⽤哈希进⾏数据分布,使⽤更多的字段通常不能得到更均匀的分布,反⽽耗费更多的时间计算。
但是实际业务可能千差万别,严格要求按照表的分布键来进行关联也不太现实,因此Greenplum还提供了复制表,即在每个计算节点上都有一份全量数据,类似于citus中的参考表,有了复制表,与复制表关联的话,就不会涉及到数据库的motion了,但是危害也是明显的,由于每个节点都有一份全量副本,因此不适合大量更新,存在写放大。
另外一种分布策略是随机分布,顾名思义,数据的分布是随机的,即便你是同样的分布键,数据也可能分布在不同的节点,这样就会涉及到数据的motion。因此除非追求极致的均匀分布 (官方说误差不超过10%),不建议使用随机分布。
存储引擎
另外一个需要提交的存储引擎,Greenplum支持Heap、AOCO、AORO。Heap即PostgreSQL堆表,因此锁模式也是相同,但是在GP6以前,还没有全局死锁检测机制,所以DELETE/UPDATE获取的是Exclusive Lock,因此DELETE/UPDATE无法并行,串行执行。
从6版本以后,引入了全局死锁检测机制,Greenplum Heap和PostgreSQL的锁矩阵模式一样,至于本地死锁检测则还是deadlock_timeout。
再说回AO表,最开始设计时,AO表被称为Append Only表,只支持追加新元组。在后来的迭代中,也支持了删除和更新元组操作,因此现在AO表指的是Append Optimized,AO表又可细分为行存和列存。AP领域当然离不开列存,行存由于是以行为形式组织存储,当需要读取某列时,需要将这列前面的所有列都进行解析,所以访问第一列和访问最后一列的成本实际上是不一样的,而列存顾名思义,以列为形式组织存储,并且由于是同一类型的数据,压缩也能更加高效,压缩比更高。另外AP领域查询通常只涉及到某些列,在这些列上进行聚合,count之类的操作,列存的优势就出来了,非常适合向量计算、JIT架构,对大批次数据计算更高效,但是劣势也不言而喻,参照之前的文章 Greenplum AO表存储分析,不适合频繁的写入更新,写放大很严重,并且一旦搭配分区表,那可能是灾难性的后果,一个列一个文件,一个分区一个数量,那么整个分区表文件数量为:
文件数量 = 分区数量 * 列数量 * 计算节点数量
对于文件系统,都可能先不堪重负尿了。这一点和单机PostgreSQL是类似的,分区表数量都要严格控制,尤其是PostgreSQL12以前的版本,另外在Greenplum中是不建议使用多级分区的。至于锁模式,AO表的UPDATE/DELETE都是Exclusive Lock,因此需要串行。
所以存储引擎的选择在建模的时候就要选择好,否则就要导入导出重写了。
索引
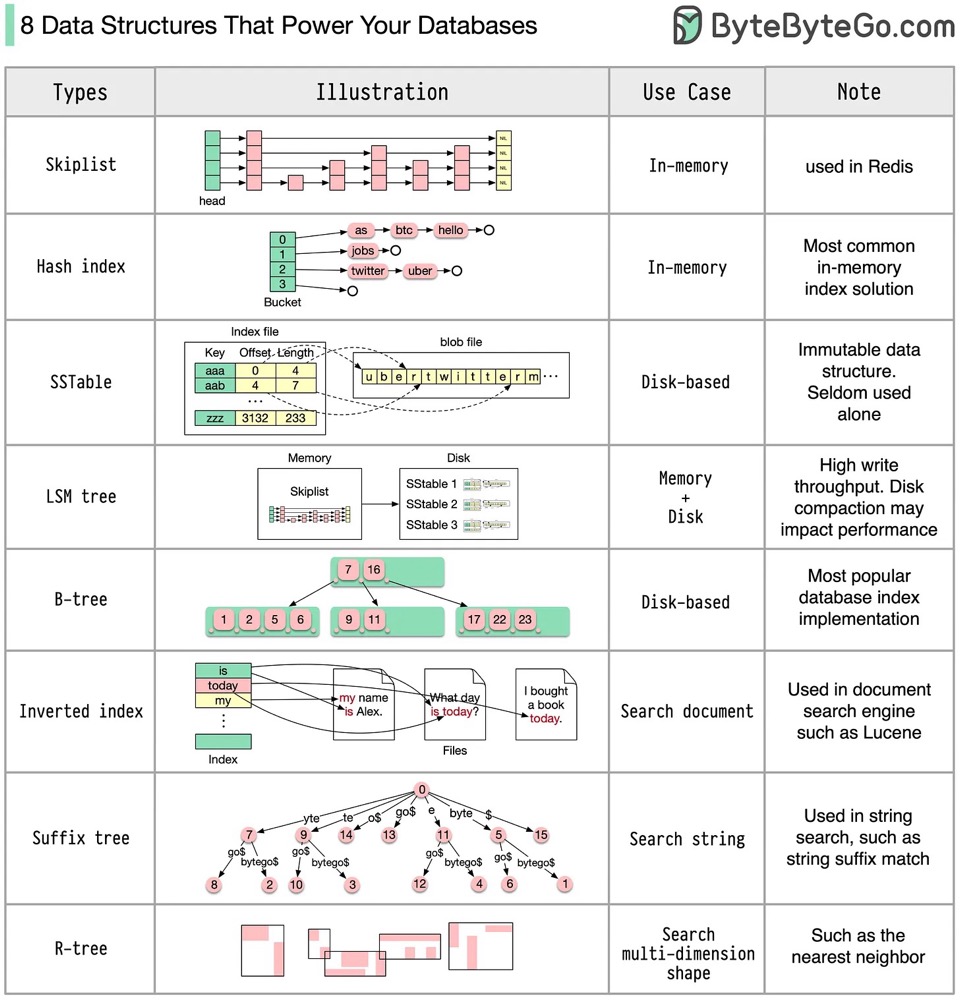
其次是索引,在AP领域,由于数据量庞大,百亿数据很常见,建个索引是十分吃力的,并且有时返回的数据量也很大,动辄几十个字段group by,这个时候索引可能就派不上用场,目前我看Greenplum还没有”虚拟索引”的概念,因此在评估是否需要创建索引时,一定要衡量好索引的选择率,以及对资源的取舍,不然建几个小时结果还是个garbage那就亏大了,Greenplum更加注重多个节点协同并行计算。另外还支持Bitmap索引,适用于那种字段重复值较高的场景。我十分喜欢bytebytego的这种图:
安装部署
在阅读GPADMIN安装部署章节之后,给我的感触也挺多。
传统集中式数据库追求的是时延,因此存储都会选择高端全闪SAN或者NVME SSD,而AP领域数据量大,就AP以及我目前接触到的领域而言,选择的大都是机械盘 + 组RAID的形式,一般选择RAID 5 + 热备盘,条带化选择256KB。因为机械盘的故障率相较SSD要高得多,可以配置一个热备盘以尽快接替故障盘。其次还需要配置IO调度策略,不过SATA口当年是慢速设备的口,就一个提交队列,再怎么电梯调度一样延时也很高,然而现在的NVME最大65536个队列 + blkmq 之后,IO调度算法都成浮云了,按照摩尔定律,现在NVME SSD的价格也已降了很多,后面随着硬件的不断革命,条件允许还是上SSD吧。
其次是SWAP的设置,和集中式数据库尽可能关闭SWAP机制不同,Greenplum主要需要考虑当计算节点主节点挂了之后,将mirror镜像节点切换为新主之后,内存不足的情况,因此需要配置SWAP (比如原来某个主机上存在4个主节点 + 4个mirror,现在激活了其中一个mirror为主节点,那么对内存和CPU的消耗就更多),这也是计算倾斜的情形之一。
一般的通用方案是,SWAP的尺寸和RAM相同。
但是在计算其他内存参数的时候,比如gp_vmem_protect_limit,不能将SWAP当做内存参与计算,在集群健康的情况下,永远不要考虑SWAP。
其次是其他组件都要考虑高可用,比如内联网络做冗余,采用bond4,提升可用性和健壮性。因此,运维Greenplum会经常与网络打交道,什么丢包、乱序都是十分麻烦的。
数据建模
Greenplum在建模上,与传统集中式数据库也存在很大差异,使⽤⾮规范化数据库模式处理MPP分析型业务时,Greenplum数据库表现优异。按照数仓领域的术语来说,采用大数据量很少变化的事实表 + 若干个小数据量维度表的雪花模型和星型模型设计会更好

其次是字节对齐,这个和PostgreSQL堆表是类似的,我在SQL优化文章中也提及过,合理地排列列的顺序可以提升性能、降低存储,何乐而不为。

小结
再次感谢作者——陈淼,无私奉献这么优质的著作,我在阅读过程中也发现了一些虫子亦或是笔误,并且也得到了作者的正向反馈,淼哥也即时进行了修订,版本迭代。假如各位有从事Greenplum相关的工作,Greenplum Database管理员指南十分值得一看。
总而言之,Greenplum虽然同为PostgreSQL系的产品,但是还是有诸多差异,但用好分布式是个技术活。