
前言
时间飞快,假期余额不足,在放飞自我的同时,学习(involution)也不能落下。
在节前,其实Greenplum7就”悄悄”release了,鸽了那么久终于与各位见面了,一起看下Greenplum7带来了哪些惹眼特性。
新特性解读
首要提及的当然是Greenplum的”芯”了,Greenplum7的内核从9.4升级到了12,直接跨越了5个大版本,毋庸置疑,性能、功能均遥遥领先于Greenplum6
Automatic Vacuum is now enabled by default for all databases, which automatically performs VACUUM and ANALYZE operations against all catalog tables, as well as runs ANALYZE for all users tables in those databases. PostgreSQL中的autovacuum我们已经十分熟悉,会定期针对达到阈值的表执行vacuum,在Greenplum中有所变化,仅对template0会执行,预防可能的事务ID回卷问题
PostgreSQL has a separate optional server process called the autovacuum daemon, whose purpose is to automate the execution of VACUUM and ANALYZE commands. Greenplum Database enables the autovacuum daemon to perform VACUUM operations only on the Greenplum Database template database template0. Autovacuum is enabled for template0 because connections are not allowed to template0. The autovacuum daemon performs VACUUM operations on template0 to manage transaction IDs (XIDs) and help avoid transaction ID wraparound issues in template0.
所以Greenplum没有worker这个说法。在以前,执行了大量的增删改之后要手动执行vacuum/analyze,同样系统表也会膨胀,比如频繁使用了临时表,会在pg_class/pg_attribute中留下垃圾,并且系统表膨胀的影响是全局性的,所以系统表也要经常性vacuum,假如系统表遇到不得不做vacuum full的场景就会很头疼。在Greenplum7中对此进行了很大改进,Greenplum会自动清理系统表以及根据可选参数清理一些辅助表,自动收集普通用户表的统计信息。
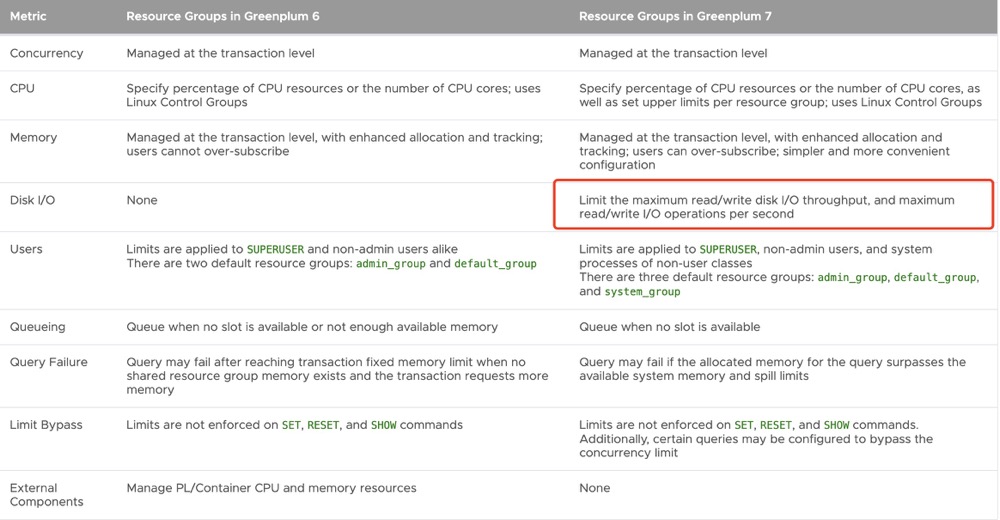
Greenplum Database introduces substantial improvements to resource group-based resource management, such as support for Linux Control Groups v2, simplified memory management, and support for disk I/O limits per resource group. 资源管理组可针对每一个组别单独设置其特定的CPU、内存和并发限制,提供数据库内部更加灵活和有效的资源管理手段,可以看到Greenplum7也支持了对IO进行限制。(Greenplum社区建议在CentOS 7.x系统中使用资源组管理资源能获得更好性能,如果是CentOS 6.x系统,则会导致明显的数据库性能下降现象,建议升级内核到 2.6.32-696或更高版本)。
- ALTER TABLE … ADD COLUMN …不再需要重写表:这个功能是PostgreSQL11引入的特性,通过在pg_attribute系统表中增加atthasmissing和attmissingval两个额外字段,所以GP7自然也支持了该功能,可以有效降低加字段所带来的影响。
| Operation | AO Columnar (AOCO) | AO Row (AO) | Heap |
|---|---|---|---|
| DROP COLUMN | No | No | No |
| ALTER COLUMN TYPE [1] | No [2] | Yes | Yes |
| ADD COLUMN (w/ non-volative default [3]) | No [2] | No | No |
| ADD COLUMN (w/ volative default) | No [2] | Yes | Yes |
| ALTER COLUMN SET ENCODING | No [2] | N/A | N/A |
| SET ( |
Yes | Yes | Yes |
| SET ACCESS METHOD | Yes | Yes | Yes |
改进的文本搜索:支持词汇和人工智能驱动的语义搜索,以提供更准确的搜索结果,提供了用于查询自然语言文档的数据类型、函数、运算符、索引类型和配置。
行级策略:基于角色的安全模型,限制用户查看表数据的权限,使得不同的用户访问一个表时可以看到不同的数据。
分区表性能与功能提升:关于PostgreSQL自身分区表的问题我已经写过诸多案例,因为严格来说,从12以后的分区表才能真正算得上是”可用”,Greenplum7引入了所有用于表分区的原生PostgreSQL语法,同时保留了旧语法,诸如split partition(拆分分区)、exchange partition(交换分区),另外需要提及的是,12的attach partition只需要在父表上添加ShareUpdateExclusiveLock了,这使得在Greenplum7中使用分区表更加便捷,当然也合并了一些pg_partition_ancestors、pg_partition_root等使用分区表函数
1 | -- Assuming there's long-running insert |
支持了MCV,默认情况下会将多列的选择率进行相乘,通过扩展统计信息可以改进优化器对于此类查询的评估
支持Brin索引,Brin特别适用于物联网、车联网等数据高速持续写入,并需要按时间区间进行分析的时序场景,索引中存储的是这些最小单位的统计信息(最大值,最小值,记录条数,SUM,NULL值条数等),并且大小相较传统Btree要小得多
支持JIT,即时编译是PostgreSQL11中的新功能之一,这可以减少多余的逻辑操作和虚函数调用,在TPC-H场景下部分查询性能提升明显
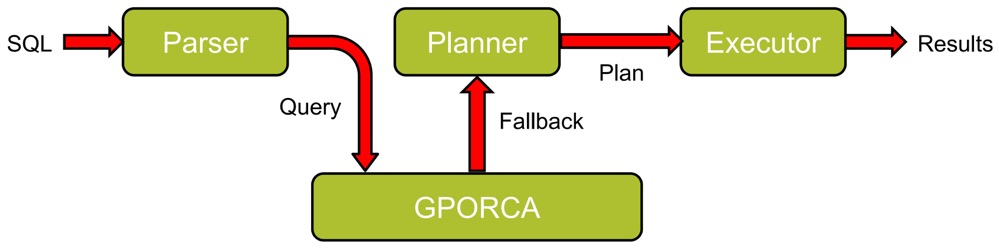
Hash indexes are supported with the Postgres-based planner and GPORCA. Greenplum支持原生PostgreSQL优化器,也支持ORCA(standard_planner 是 PostgreSQL 缺省的优化器),对于GPORCA不支持的特性,GPORCA会自动回到Planner。可以看到,Greenplum7对于两种引擎,都支持了哈希索引
引入了pg_stat_progress_vacuum/copy/create index等进展视图,执行此类维护性操作时不再是黑盒,有迹可循
支持了generate column,符合SQL标准,也可以解决序列的诸多”黑洞”,参照序列七宗罪文章
引入了pgvector,分布式+向量化多专场景
更多信息可以参考 https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/relnotes-release-notes.html
小结
一张图概括Greenplum7新特性。

简而言之,Greenplum7的release使得Greenplum的HTAP能力更近一步,能够提供包含实时处理、弹性扩容、混合负载、集成数据分析等,也让我相信”超融合”会是个大趋势,将简单留给用户,复杂留给自己,皇帝数据库PostgreSQL当仁不让。
参考
https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/relnotes-release-notes.html
https://docs-cn.greenplum.org/v6/best_practices/bloat.html
https://greenplum.org/alter-table-in-greenplum-7-avoiding-table-rewrite/