
前言
昨晚 PostgreSQL16 正式 release 了,最近的几个大版本有点挤牙膏,没有前几个大版本那么惊艳,主要是一些细节的迭代,虽乏善可陈,但还是有几个特性我觉得值得称道一下。
pg_stat_io
首先我最感兴趣的是 pg_stat_io,顾名思义——I/O 类的统计信息
1 | postgres=# \d pg_stat_io |
在 16 以前 I/O 类的统计视图包括诸如 pg_stat_database.hits/reads,pg_statio_all_tables.hits/reads,pg_stat_bgwriter.backend_write 等,但是你无法知悉是哪个进程做了什么 I/O,I/O 又可细分为 flush(刷盘)、evict(页面置换)、extend(数据块扩展)、是否是bulk read/write、特殊情况比如表空间之间移动、临时文件等等,以 insert 为例,大致流程是:
- 通过 fsm 找到一个可以容纳元组的数据块
- 如果没有满足的数据块,则需要 extend,至于一次性扩展多少个数据块是自适应算法,此处不做展开
- 如果数据块在 shared buffer 中没找到,则还需要发生 I/O,将数据块读入
- 如果 buffer 区已满,还需要先做 buffer 的置换——eviction,如果是脏的数据块,还得进行刷盘
因此一个简单的插入就可细分为多个子项,在 pg_stat_io 中,将 flush 和 extend 进行了分开,为什么要这么做?因为 extend 这个动作是无法避免的,比如批量导入、copy from 的时候会进行大量 extend,而数据块的 flush 是延迟写入的,将这二者分开为调优提供依据。
其次可以看到 context 字段,为什么要跟踪每个 I/O 的上下文?我们知道,buffer pool 并不是用于所有的 IO,比如 ring buffer,当读取的表数据量超过了 25% 的 shared_buffers 就会用到 ring buffer,预防 buffer pool 被批量污染,比如批量导入的时候也会用到 (copy from,create table as 等等)。有了 pg_stat_io 提供的基准数据,我们便能更加灵活、更有针对性地去调整,在之前的版本我们是无法知悉此类批量读取导入的行为的。
让我们看几个实际例子:数据块刷脏,我们知道 bgwriter 应该是写入主力,但是下面的数据却显示了 bgwriter 太过于懒惰,后端进程参与了很多写入操作,这会大大增加后端进程的延迟,因此我们需要去调整 bgwriter 相关的参数。
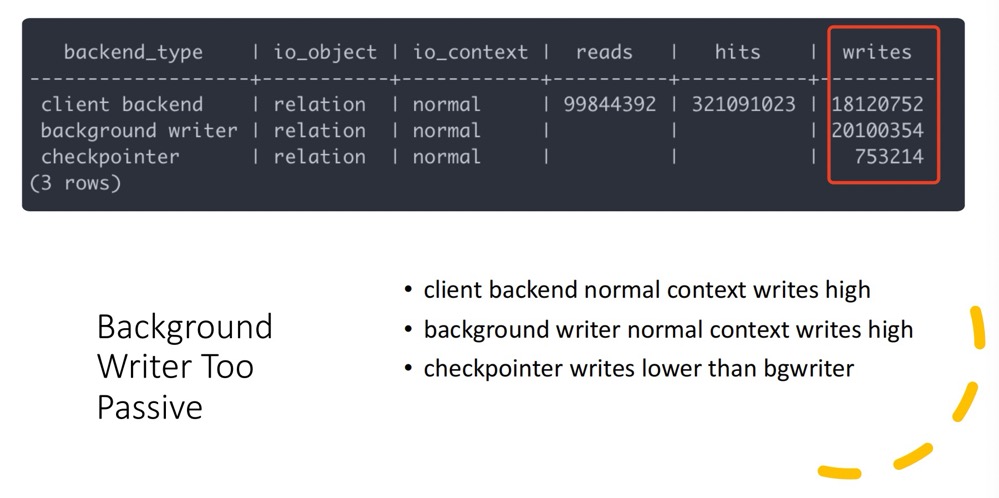
又比如你发现了大量的 evictions,那么意味着 shared_buffers 可能需要调整。
另外值得一提的是 pg_stat_user_indexes 增加了 last_idx_scan 字段,可以让我们获取最近未使用过的索引列表。在以前的版本是无法直接查找在给定时间段内是否使用过某个索引的,last_idx_scan 字段使我们分析索引使用效率更加便捷。
并行回放
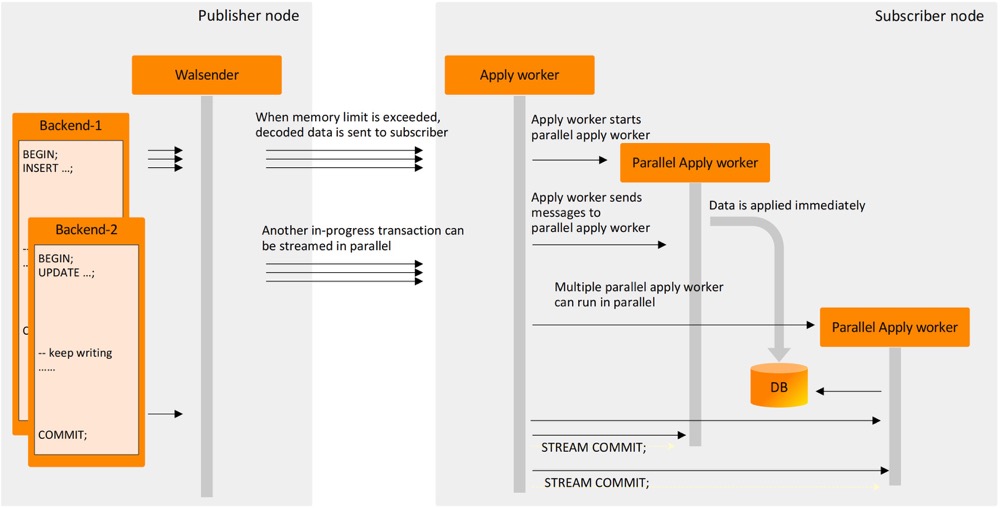
逻辑解码也有很多亮眼特性。首先是并行回放,对于”流式”事务 (流式 decoding 和发送,无需等待事务结束) ,订阅端无需等待发布端事务提交,并且可以创建多个 apply worker 并行回放 (每个事务一个 apply worker),进一步提升事务的处理能力,据测试显式,大约有 25% ~ 40% 的性能提升,不过具体效果会怎么样,还需要经过时间的验证,早期版本的并行也会有各种各样的 BUG,举个栗子,当 leader apply worker 和 apply worker 回放过程中遇到死锁冲突能否妥善处理。
Each large transaction is assigned to one of the available workers.
复制标识
在 16 以前,如果 replica identity 使用的是 full 模式 (即没有主键也没有合适的索引作为身份标识),那么每一行订阅都会导致在订阅端全表扫描一次,很容易将订阅者拖垮。在 16 里有所改善,对于这种情况可以使用索引扫描了,但限制是必须 BTREE,也不能是部分索引,并且至少引用了其中一列,因为 15 支持了 column-fliter,仅对某些列进行发布。这种行为使得兜底方案 full 模式的性能也得以较大提升。
The index that can be used must be a btree index, not a partial index, and it must have at least one column reference
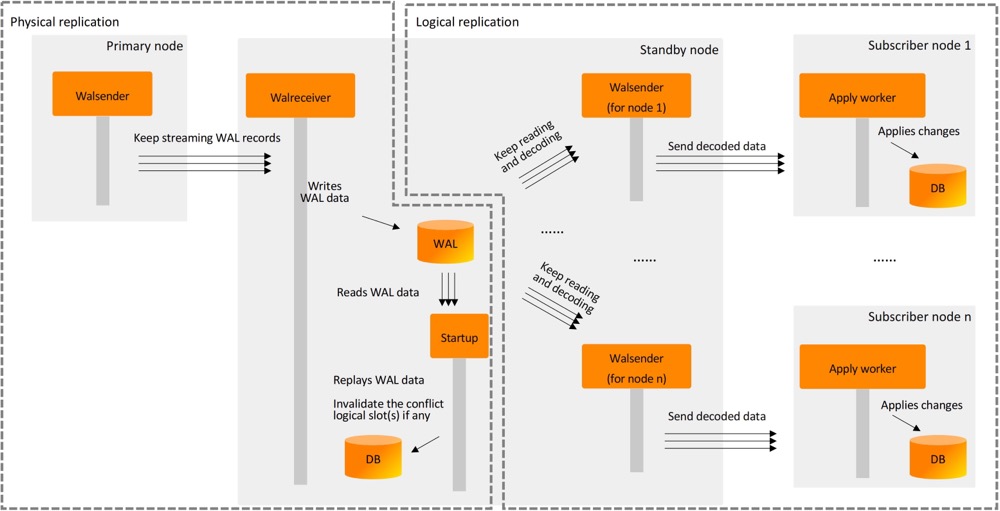
备库支持逻辑解码
This can be used for workload distribution by allowing subscribers to subscribe from standby when primary is busy
备库支持逻辑解码也是一项较大的提升,以减轻主库的压力。要求主库和备库都设置为 logical,当然这就会涉及到类似流复制冲突了,我们可以查看 pg_replication_slots.conflicting 字段,比如需要的字段在主库上被删了,或者主库将 wal_level 设为了小于 logical 的等级,这个时候备库的复制槽会变成 invalide 的状态。
This feature allows workload distribution by allowing subscribers to subscribe from standby when primary is busy.
双向复制
16 进一步完善了对于双向复制的支持
Finally, this release begins adding support for bidirectional logical replication, introducing functionality to replicate data between two tables from different publishers.
双向复制我们知道,主要是 WAL 无限循环的问题,参照下图 👇🏻
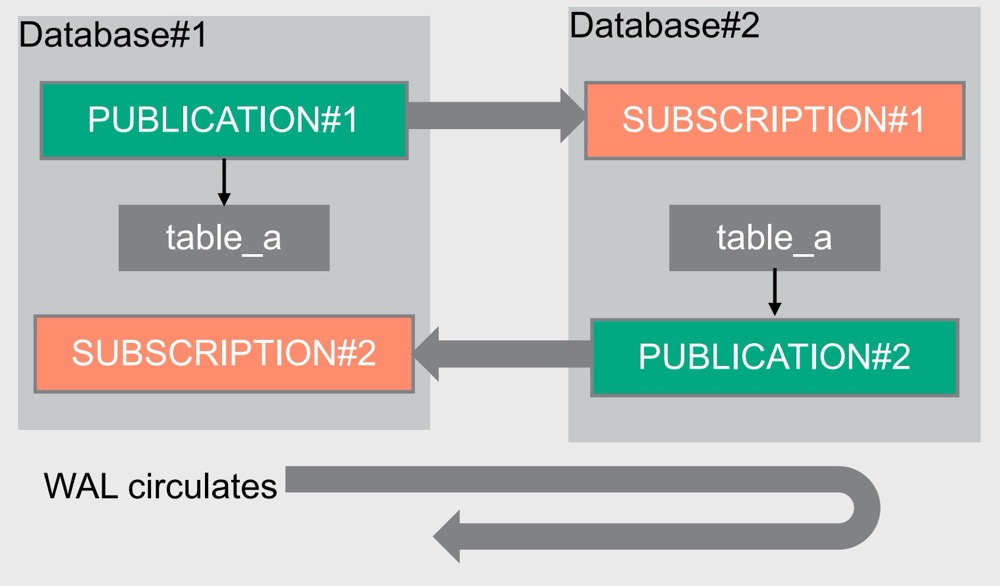
这个时候便需要用上 origin——用于标识数据的来源。oragin 可以自动创建 (创建发布) 也可以手动创建 (pg_replication_origin_create),这样 WAL 中便会记录 record 的来源。
那么在 16 里面增加了什么内容呢?我们在创建订阅的时候可以指定 origin
Specifies whether the subscription will request the publisher to only send changes that don’t have an origin or send changes regardless of origin. Setting
origintononemeans that the subscription will request the publisher to only send changes that don’t have an origin. Settingorigintoanymeans that the publisher sends changes regardless of their origin. The default isany.
看个例子
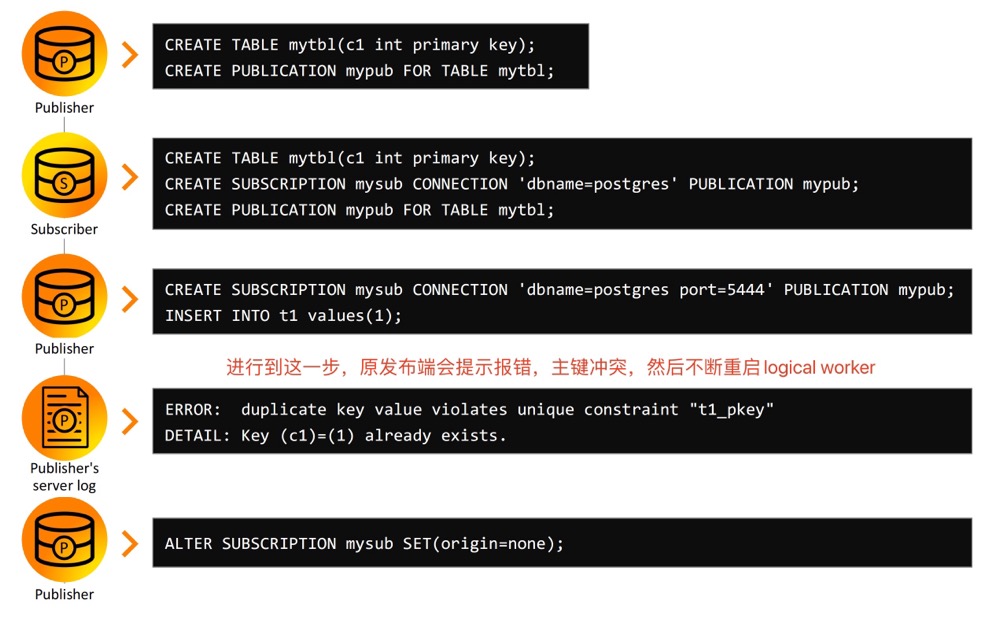
在第④步的时候,发布端会一直报错,提示主键冲突,不断启动新的 worker,如此往复
1 | 2023-09-15 14:07:56.332 CST,,,3704,,6503f4bc.e78,1,,2023-09-15 14:07:56 CST,5/185,0,LOG,00000,"logical replication apply worker for subscription ""sub2"" has started",,,,,,,,,"","logical replication worker",,0 |
以往这个时候如果不含主键就会不断双向复制,直至撑爆磁盘。在 16,支持设置 origin了,前面也说了,WAL record 里面会包含 origin,用于标识数据的来源 👇🏻
1 | rmgr: Transaction len (rec/tot): 57/ 57, tx: 853, lsn: 0/0D089878, prev 0/0D089838, desc: ABORT 2023-09-15 14:09:16.391953 CST; origin: node 1, lsn 0/0, at 2000-01-01 08:00:00.000000 CST |
可以看到 origin:node 1。将 origin 设为 none,意味着订阅端要求发布端只发送不含有 origin 的数据
1 | postgres=# alter subscription sub2 set (origin = none); |
订阅端插入一条新的数据
1 | postgres=# show port; |
发布端查看
1 | postgres=# select * from t1; |
可以看到,实现了双向复制!前进的一大步!
libpq负载均衡
1 | $ psql 'host=localhost,localhost,localhost port=16010,16020,16030 load_balance_hosts=random dbname=testdb' - |
性能提升
详细细节可以参考 https://www.postgresql.org/docs/16/release-16.html,此处列出一些值得关注的。
direct_io,Currently this feature reduces performance, and is intended for developer testing only.,PostgreSQL 目前 double buffer 的机制,会导致性能不稳定,尤其是当操作系统在做 direct memory reclaim 的时候,虽然目前 direct_io 还没有直接向用户开放,但是你可以使用 debug_io_direct 参数进行测试, The further plan is to introduce our own I/O mechanisms, read-ahead, etc. to replace the facilities the kernel disables with this option. 生产暂时不推荐,但是相信走出了这一步,后续对于 direct_io 的支持会逐步完善
表在扩展数据块速度更快,锁的粒度降低
Allow freezing at page level during vacuum,在 vacuum 期间允许 freeze,减少冻结炸弹的影响
Provides significant improvement (3X for 16 clients) for concurrent COPY into a single relation,提升 COPY的导入性能
parallel hash full join、parallel aggregate on string_agg and array_agg
Allow aggregates having ORDER BY or DISTINCT to use pre-sorted data,以往在聚集之前需要先对数据进行排序,现在通过索引可以提供 pre-sorted 的输入直接用于聚集
Allow left join removals and unique joins on partitioned tables
Support for CPU acceleration using SIMD for both x86 and ARM architectures,Optimizations for processing ASCII and JSON strings, and subtransaction searches
Added LZ4 and Zstandard compression options to pg_dump
Allow COPY into foreign tables to add rows in batches
collate:Allows ICU to be the default collation provider,CREATE COLLATION en_custom (provider = icu, locale = ‘en’, rules = ‘&a < g’);
Cache the last found partition for RANGE and LIST partition lookups,用于提升导入的性能 (连续的数据可能会导入到某一个分区中)
JSON支持
Added LZ4 and Zstandard compression options to pg_dump
Allow COPY into foreign tables to add rows in batches
Improve speed of hash index builds
Improve performance of and reduce overheads of memory management, Reduce the header size for each allocation from 16 or more bytes to 8 bytes
vacuum_defer_cleanup_age参数被移除,很多BUG!(参照之前文章)
explain 支持查看通用执行计划
1 | postgres=# explain (generic_plan) select * from pg_class where relname = '$1'; |
小结
16 大版本虽然还是没有解决那些老顽疾,但是仍有不少惹眼特性,赶紧试用起来吧!推荐阅读 👇🏻
参考
https://www.postgresql.org/docs/16/release-16.html
https://www.cybertec-postgresql.com/en/postgresql-v16-cool-new-features/
PostgreSQL 16 and beyond