
前言
今天在 2 群里一位筒子提了这样一个问题
我们最近很多报表在读复制从节点的数据,但从节点的 pg_stat_all_tables 里面好像最后vacuum 和 analyze 的时间都没有,这个统计数据或者 vacuum 操作会在从节点也重放吗
首先可以肯定的是,vacuum 操作肯定会在备库回放,不然何来 snapshot conflict呢。所以 2 群某位小伙伴的如下观点是错误的
从库不会 vacuum,只会同步主库的元组变更
问题很明了,备库的 pg_stat_all_tables 里面的 vacuum / analyze 相关字段没有数据,导致读取出来的数据没有意义。正好昨天把狂飙电视剧追完了,也需要重拾一下烂笔头了。
闲话少叙,让我们一起分析一下这个问题!
复现
首先简单搭建个主从,然后主库上模拟几条操作
1 | postgres=# create table test(id int); |
可以看到自动触发了 autovacuum,手动执行 vacuum 也有记录。那去备库上瞅瞅
1 | postgres=# select relname,last_vacuum,last_autovacuum,last_analyze,last_autoanalyze from pg_stat_all_tables where relname = 'test'; |
果然,不仅 vacuum 相关的字段没有数据,其他字段也没有数据,而且备库也无法执行这类写操作。那为什么会产生的差异呢?
分析
先从源头出发便可发现端倪,pg_stat_all_tables 原来仅仅是一个视图,just a view!并非表对象,是一个关于表上各个维度的计数器 👇🏻,这个统计的过程由 stats collector 进程来做。
1 | SELECT c.oid AS relid, |
再回想一下我之前写过的关于统计信息收集的基础原理 👇🏻
每个进程执行 DML 会去调用 pgstat_report_stat 向 stats collector 进程反馈统计信息,后面会通过 pgstat_send_tabstat 发送表的统计信息,其他的诸如 函数/WAL/SLRU的统计信息,则会有对应的三个函数 pgstat_send_funcstats/pgstat_send_wal/pgstat_send_slru 来完成。
每个后端进程在事务提交/回滚时会发消息给进程 stats collector,stats collector 会汇总这份信息并记录到文件中,然后 autovacuum launcher 定期读取文件以决定何时触发 autovacuum vacuum进行工作。而 pg_stat_all_tables 所涉及到的 pg_stat_get_tuples_* 这类相关函数正是与 stats collector 进程打交道的,但是统计信息所涉及到的相关文件(pg_stat_tmp / pg_stat 目录下)又不会被复制到备库。纳尼?不会复制到备库,为什么不会复制到备库?
卖个关子,各位思考五分钟。
回顾一下流复制的原理,流复制本质上就是基于 WAL record 的流式传输,主库 walsender 进程解析 WAL record 发送到备库,备库 startup 进程再进行回放,而 pg_stat_tmp 这类文件非普通对象,都不会记录 WAL record,那么自然不会复制到备库。
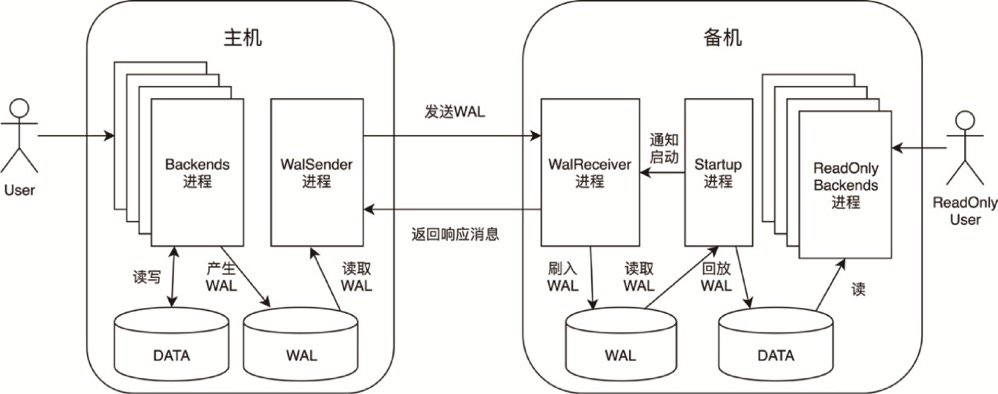
除此之外,其实还有个细节可以侧面证明,一般我们搭建流复制都是使用 pg_basebackup,而 pg_basebackup 在备份的过程中是会跳过一些文件的
1 | /* |
1 | /* Scan for directories whose contents should be excluded */ |
可以看到 PG_STAT_TMP_DIR便被跳过了。所以备库没这个文件
1 | [postgres@xiongcc ~]$ ll 14data/pg_stat_tmp/ |
让我们验证一下,这里为了演示,使用 14 版本,因为在 15 的版本以后移除了 stats collector 进程,pg_stat_tmp 目录继续保留主要为了一些插件,比如 pg_stat_statements。
1 | postgres=# select pg_backend_pid(); |
另一个终端用 strace 抓一下
1 | [postgres@xiongcc ~]$ strace -p 19224 |
很清晰了,该进程去读了 pg_stat_tmp 目录下的 db_13892.stat。不过值得注意的是,备库是可以自己做checkpoint的,目的是避免每次重启备库都需要从上一个检查点(由主库产生,在WAL中回放出来的)回放后面所有的WAL,但是注意并不会去更新控制文件相关的位点,因为是从主库同步过来的。所以,备库执行了checkpoint,会生成相关文件。不过还是那个问题,刷到存储上的是备库”此时”的状态,所以还是0。
1 | [postgres@xiongcc ~]$ ll 14data_bak/pg_stat_tmp/ |
小结
通过这个小案例,其实我们也能发散一下思维,思考的更深一点:
autovacuum launcher 定期读取 stats collector 进程收集的统计信息文件以决定何时触发 autovacuum,而备库是不包含此类统计信息文件的,因此假如有个表在主库上即将达到了触发阈值就快要进行 vacuum/analyze 了,结果这个时候做了一个 switchover 或者 failover,新的主库由于没有统计数据,需要新的活动才可以触发收集,因此这个表就会被”延迟”清理,时间可能就增加了一倍。怎么样,是不是 get 到了一波奇怪的知识。虽然大多数时候不会引起实质性的问题,但是假如系统在处于那种极端情况下,刚好这个表统计信息收集不及时,导致了性能问题,那么买个彩票吧。
同理,vm文件也不会进行复制,假如有个表要插入新行了,switchover 或者 failover 后第一次 vacuum 之前都不会复用这些空间,所以极端情况下可以做个 vacuum。
主库正常DML,每个进程执行 DML 后会去调用 pgstat_report_stat 向 stats collector 进程反馈统计信息,然后 stats collector 收集这些活动(比如插入了多少条,删除了多少条,更新了多少条等等)汇总到 pg_stat_tmp/pg_stat 文件中,然后 autovacuum launcher 定时读取 pg_stat_tmp/pg_stat 目录下的文件以决定何时触发 autoanalyze / autovacuum,比如触发了 analyze,就去进行收集统计信息,参照之前文章里面所写的收集机制 👇🏻
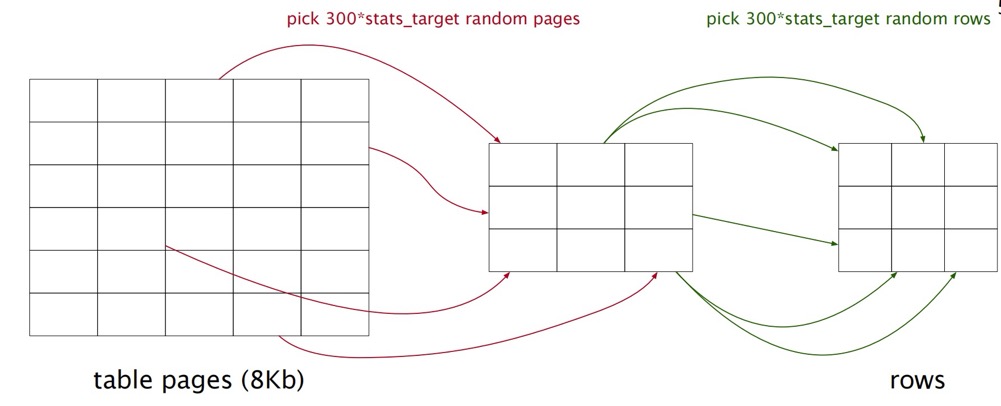
默认情况下,采集的行数会有个限制,最小100行,最大 300 * default_statistics_target ,不足100行的话,则获取全部数据,随机获取数据块,随机获取数据,假如数据量足够的话,默认随机选择 300 * default_statistics_target 个数据块,然后从中随机选择 300 * 300 * default_statistics_target 行数据。
另外我发现最近很多人在问 PostgreSQL 巡检的事,正好我也有这个打算,使用 go 开发一个巡检工具,一来拾起生疏的 go,二来想着自己撸一个巡检工具出来,我行我上,拭目以待吧。
真是一个有趣的案例啊!好了,That’s all,我又要去追三体了。
参考
https://blog.51cto.com/yanzongshuai/2381680
https://stackoverflow.com/questions/63125306/postgres-stats-on-the-new-primary