
前言
昨天一位同事把我拉到群里,说到这么一个现象:”业务过程中只要涉及到 xxx_user_info 表的查询,都出现堵塞和慢查询了”,后面经过询问,原来在出现堵塞的时候,在数据库里执行了几条添加字段的操作
- ALTER TABLE xxx_user_info ADD COLUMN sex varchar(4) default ‘’;
- ALTER TABLE xxx_user_info ADD COLUMN phone varchar(500) default ‘’;
其实到这里,老油条应该已经能猜到导火索了,没错加列这个操作是会获取 AccessExclusiveLock锁的,最重的 8 级锁,会和一切操作阻塞,那么碰到这种类似的情况我们作为 DBA 该如何巧妙地把锅甩回去呢?
分析
如前文所说,加列操作属于 DDL,因此也要获取 8 级锁,从 11 版本以后,添加字段就变得 easy 多了,新增带默认值的字段可以不用重写表,通过pg_attribute中的atthasmissing和attmissingval来标识,当然也需要分情况:
- 新增的默认值假如是一个常量,不需要重写,比如 alter table test add column info text default ‘hello’ not null;
- 新增的默认值假如是 stable 或者 immutable 类型的函数,不需要重写表,比如 alter table test add column t_time timestamp default now() not null;
- 新增的默认值假如是 volatile 类型的函数,需要重写表,比如 alter table test add column id int default random() not null;
因此 ALTER TABLE 这个操作不需要重写表,不管表大表小都是”秒加”,秒级完成,只要系统表修改一下即可。
那么为什么开发还会说:”测试环境试了下,并发压测的情况,ALTER TABLE ADD COLUMN的操作很快,但是生产环境中这个操作就一直卡住,十分的慢,为啥 ALTER TABLE 会那么慢呢?不仅ALTER TABLE不成功,查询也慢,如果 ALTER TABLE 抢不到锁的时候,不会给我把表锁住影响到 SELECT 吧”,以上来自我和开发的真实对话😵💫… 既然不会重写表,为什么这个ALTER TABLE会那么慢?其实不是 ALTER TABLE 执行慢,而是等得慢!虽然加列操作是秒级完成的,但是这个操作是需要获取短暂的 AccessExclusiveLock 锁,因此对于高并发的系统,表上无时无刻不在做读写,随时都有锁,因此这个 ALTER TABLE 极有可能抢不到锁,给人的错觉就是这个操作做了很久,一旦抢到了,就立马完成。如下 👇🏻
- A表上持续有读取写入,需要获取表上的 AccessShareLock 和 RowExclusiveLock
- A表上现在做加列操作,需要获取表上的 AccessExclusiveLock,获取失败需要排队,等待前面读取查询完成
- A表上后续新来的查询写入,也处于等待,等待加列完成,因此形成了一个锁的队列
表级锁(我们常说的重锁)之间会形成一个公平的等待队列,如果某个进程尝试获取现有的不兼容的锁,那么该进程就会进入到队列中,等待进程不会浪费 CPU 时间:它们会进入休眠状态,直到锁被释放并且操作系统将它们唤醒。举个栗子,假如 A 表现在有查询读写,现在第二个会话想要创建索引,那么就需要等待,然后来了第三个会话,想执行 vacuum full,那么他也会加入到队列,假如这个时候又来了一个查询,这个查询会阻塞吗?答案是也会,所有后续的会话都必须加入到队列中,而不管锁的模式如何,尽管查询的 AccessShareLock 与第一个和第二个会话的锁不冲突
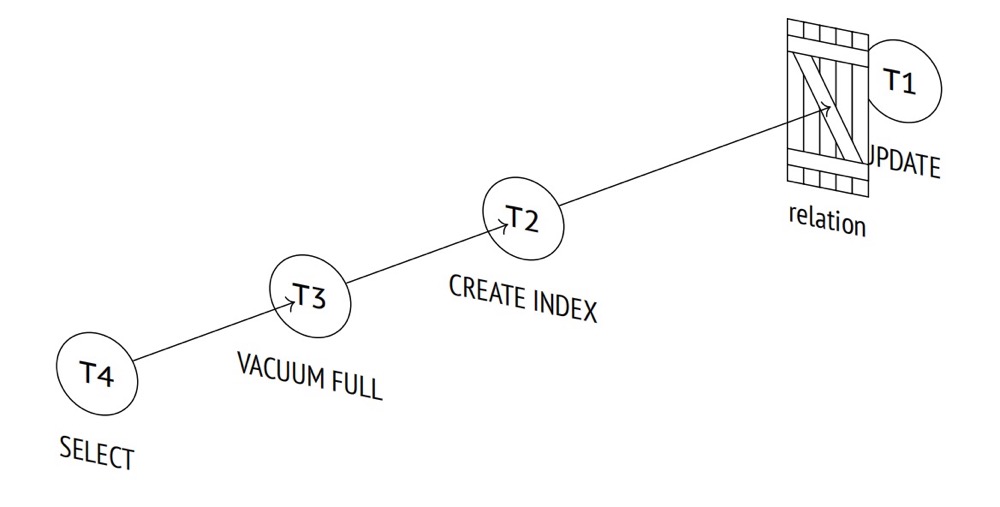
所以为什么开发会说做了加列操作会导致查询也慢,现在各位应该弄懂了,其实不是慢,而是在等待,等的慢!因此正确的姿势是在做重操作比如 DDL 之前,手动添加 lock_timeout,主动报错,防止雪崩。
online DDL
最近我经常在其他数据库群里潜水,看的比较多的一点就是,MySQL DBA在吐槽——PostgreSQL没有online DDL!虽说大多数的操作比如加列、删列(系统表修改)啥的都可以秒级完成,丐版的online,但是架不住也需要获取到锁才能进一步操作,对于高并发的系统很有可能获取不到,就比如上面这个案例,那么有没有一种办法可以处理一下呢,把锅甩回去?有个插件可以帮到我们:pg_migrate,看下介绍 👇🏻
pg_migrate is a PostgreSQL extension and CLI which lets you make schema changes to tables and indexes. Unlike
ALTER TABLEit works online, without holding a long lived exclusive lock on the processed tables during the migration. It builds a copy of the target table and swaps them.
pg_migrate 灵感来源于 pg_repack,所以和 pg_repack 的原理类似,拷贝副本、触发器抓取增量数据、最后做个交换,操作方式也是类似,包括 CLI 也是如出一辙:
1 | [postgres@xiongcc ~]$ pg_migrate --help |
看个例子,假如现在有个大表,需要加列 alter table test_big add column t_time timestamp default clock_timestamp(),按照前面的分析,此操作会重写表,在重写期间会全程持有8级锁,无法读写,试一下
1 | postgres=# begin; |
新开会话
1 | postgres=# begin; |
那让我们用 pg_migrate 试一下,和 pg_repack 类似,需要主键或者唯一键,目前还是在试运行,dry run,会将运行过程中可能的错提前报出来
1 | [postgres@xiongcc ~]$ pg_migrate -t test_big --alter='add column t_time timestamp default clock_timestamp()' |
现在真正跑一下,跑的过程中再次执行一个插入
1 | postgres=# select relfilenode,oid,relname,pg_relation_filepath(relname::regclass) from pg_class where relname = 'test_big'; |
可以看到类似的触发器用于捕获增量
1 | postgres=# \d+ test_big |
另一个会话老样子插入一下,可以看到并不会阻塞,这就解决了一大痛点了!
1 | postgres=# begin; |
一段时间过后,pg_migrate 显式在等待某个进程,而这个进程正是刚刚插入的进程,提交完成之后,pg_migrate也就执行成功了
1 | [postgres@xiongcc ~]$ pg_migrate -t test_big --alter='add column t_time timestamp default clock_timestamp()' --execute |
表结构顺利变更
1 | postgres=# select relfilenode,oid,relname,pg_relation_filepath(relname::regclass) from pg_class where relname = 'test_big'; |
限制
- Unique constraints are converted into unique indexes, they are equivalent in Postgres. However, this may be an unexpected change.
- Index names on the target table and foreign key constraints are changed during the migration.
- If the generated names are > 63 characters, this will likely break
- If the target table is used in views, those objects will continue to reference the original table - this is not supported currently.
- If the target table is used in stored procedures, those functions are stored as text so are not linked through object IDs and will reference the migrated table.
- DDL to drop columns or add columns without a default is not currently supported
- Hosted PG databases (RDS, Cloud SQL) are not supported because they do not allow installing custom extensions.
小结
可以看到,pg_migrate 起源于 pg_repack,操作和原理基本一模一样,所以限制也是类似的,虽然不会阻塞读写,但是可以有效避免长时间持有重锁,同时也会和 pg_repack 一样默认情况给你把阻塞会话干了
1 | [postgres@xiongcc ~]$ pg_migrate -t test_big --alter='add column t_time timestamp default clock_timestamp()' --execute --wait-timeout='5' |
所以对于关键的业务系统,记得加上 –no-kill-backend,做的期间最好也不要有什么DDL。